wzs
2022 年6 月 28 日 01:49
1
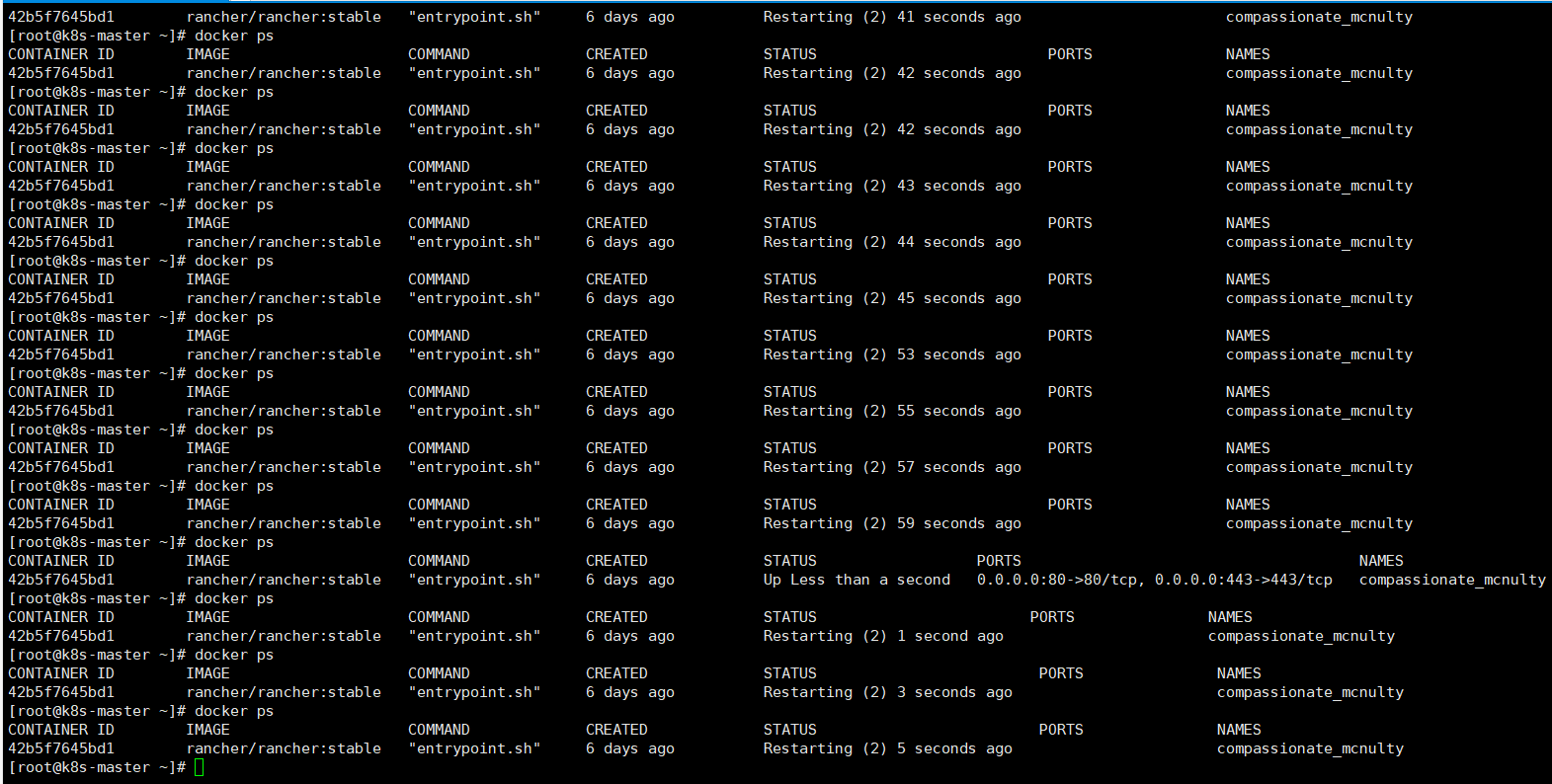
rancher/rancher:latest “entrypoint.sh” 4 days ago Restarting (2) 46 seconds ago cranky_jang。几十秒就重启一次无休无止。
通过docker logs 查看发现报错如下:
不知道这个该怎么解决。每次开机都这样。。。
参考以下帖子:
你发出的日志,看起来不足以造成rancher crash。
wzs
2022 年7 月 4 日 01:03
3
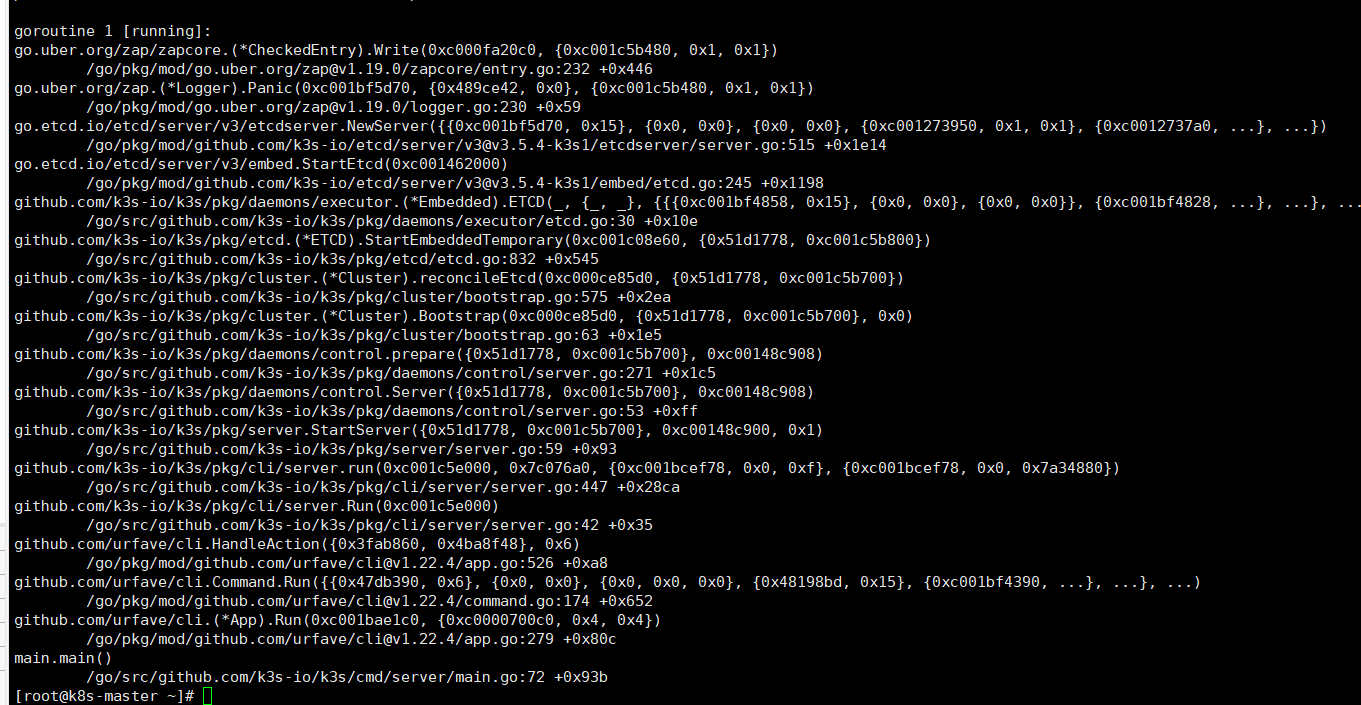
etcdserver: recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file doesn’t exist)
panic: recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file doesn’t exist)
goroutine 1 [running]:go.etcd.io/etcd/etcdserver.NewServer.func1 (0xc00025add0, 0xc000258ce8)github.com/coreos/pkg/capnslog.(*PackageLogger ).Panicf(0xc0001ba980, 0x10cc379, 0x2a, 0xc000258db8, 0x1, 0x1)go.etcd.io/etcd/etcdserver.NewServer (0x7ffe552d9d47, 0xe, 0x0, 0x0, 0x0, 0x0, 0xc000118f00, 0x1, 0x1, 0xc000119380, …)go.etcd.io/etcd/embed.StartEtcd (0xc000222000, 0xc0000f7600, 0x0, 0x0)go.etcd.io/etcd/etcdmain.startEtcd (0xc000222000, 0x10a10f9, 0x6, 0x1, 0xc0001c3110)go.etcd.io/etcd/etcdmain.startEtcdOrProxyV2() go.etcd.io/etcd/etcdmain.Main()
每次VMware虚拟机断电重启,都会报上面的snap文件不存在,从而rancher无限启动,有没有什么解决办法。
这是个很复杂的问题。etcd本身对运行环境的要求就相对严格。
另外建议你按照模板填写帖子内容,不要特意删除或者不提供那些信息。你把一些上下文沟通的信息删除,其他人很难判断你的问题。
wzs
2022 年7 月 4 日 01:58
5
我的虚拟机启动后,rancher 容器一直restartfing,但是就是up不起来,查看docker 日志,报错如下:
7月 04 09:52:03 k8s-master kubelet[7112]: Flag --cgroup-driver has been deprecated, This parameter should be set via the config file specified by the Kubelet’s --config flag. See Set Kubelet parameters via a config file | Kubernetes for more information.
/var/lib/kubelet/config.yaml,这个文件为啥缺失呢,难道机器断电就没了吗,需要怎么才能能恢复呢。
ksd
2022 年7 月 4 日 02:25
6
你的日志只有这些? 上面的 etcd 日志不刷了?
wzs
2022 年7 月 4 日 03:54
7
启动rancher容器的时候,不需要etcd;etcd那个日志是集群机器报错的。我想的是,如果rancher都启动不起来,他管理的集群肯定就启动不了。所以看能不能先解决启动rancher容器的问题。
ksd
2022 年7 月 4 日 05:47
8
你理解错了,rancher 起来起不来,不会影响你的下游集群。
就算你把 rancher 删掉了,你的下游集群依然正常运行,你可以继续使用 kubectl 去管理
wzs
2022 年7 月 4 日 06:05
9
那先不管下游集群,我这个rancher,它就是一直restart,连续几次去刷新容器状态如上截图所示。
这个有什么解决思路吗。我的rancher版本是2.6稳定版本。
ksd
2022 年7 月 4 日 08:33
10
你上面发了两个日志,一个是 etcd 的一个是 kubelet 的,我不知道你的 rancher server 是因为哪个日志终止了
wzs
2022 年7 月 4 日 08:53
11
etcd那个日志,是下游集群机器的日志,既然你说集群启动跟rancher没有关系,那我们就先不管他。我后面发的那个一直restart的rancher容器日志,是在安装rancher机器上输入“journalctl -xe”命令出来的。
ksd
2022 年7 月 4 日 09:53
12
你 docker logs -f 42b 看看 rancher server 的日志,看看最终是什么原因导致的容器宕掉了
wzs
2022 年7 月 8 日 00:27
13
报错如上,只要断电重启就一直restarting,好无奈呀
wzs
2022 年7 月 8 日 01:42
14
{“level”:“panic”,“ts”:“2022-07-08T01:32:45.396Z”,“caller”:“etcdserver/server.go:515”,“msg”:“failed to recover v3 backend from snapshot”,“error”:“failed to find database snapshot file (snap: snapshot file doesn’t exist)”.
不知道是不是这个原因没有起来。