问题描述
大学生一枚,计算机专业但非 devops 方向,k3s 为个人兴趣爱好。2023-01-23 搭建个人用 k3s 集群,目前稳定运行 469 天。但每当有新节点加入集群后,所有 agent 都会无法访问自己的 http://127.0.0.1,server 无此问题。前几次新节点加入后不知道在哪个操作后问题就不在了,这次新加入两个节点后问题又出现了,尝试重启 klipper 和 k3s-agent 均无效。
目前 CDN 回源全部配置到了 server 的 IP,所以 agent 无法提供 web 服务也不会对业务产生影响,但还是希望能解决这个问题,所以前来提问。
集群配置
集群有 1 台 server 和 5 台 agent,其中 4 台 agent 正在使用,另有 3 台 agent 已移出集群
- k3s-sh1-new(server
- k3s-sh-tx-2
- k3s-sh-tx-3
- k3s-ty-nasvm-1(目前 NotReady,SchedulingDisabled
- k3s-sh-ali-3(本次新加入的两个节点
- k3s-sh-ali-4
整个集群跨多个城市,所以下层网络选用了 ovpn。与集群相同,server 节点的 ovpn 也是 server,agent 节点的 ovpn 也是 agent。ovpn 网段为 10.150.0.0/16,在所有机器上均使用创建的 tun0 网卡工作。
已经确认下层网络没有任何问题(例:各机器之间相互访问 10250 等端口均正常)。
值得一提的是,每次加入新节点后,为确保网络正常工作,我会手动重启所有机器上的 ovpn 服务,重启会造成一秒左右的闪断。重启完成后我会再次确认各机器直接能够相互连通。
除 k3s-ty-nasvm-1 不在运行外,所有机器均设置了正确的 node-name、node-ip 和 node-external-ip,且所有 IP 均可用。
网络方面,仅 disable 了 traefik 并替换为 ingress-nginx。flannel、klipper、coredns 均未做任何修改。IPv4 单栈。flannel 后端为默认 vxlan,klipper 模式为默认 nft。
server 的存储为 MySQL。
初始化方面,集群所有机器均安装 Ubuntu 22.04 并完全执行一个相同的脚本,只有 k3s 启动参数有不同。各机器的启动参数在下文。
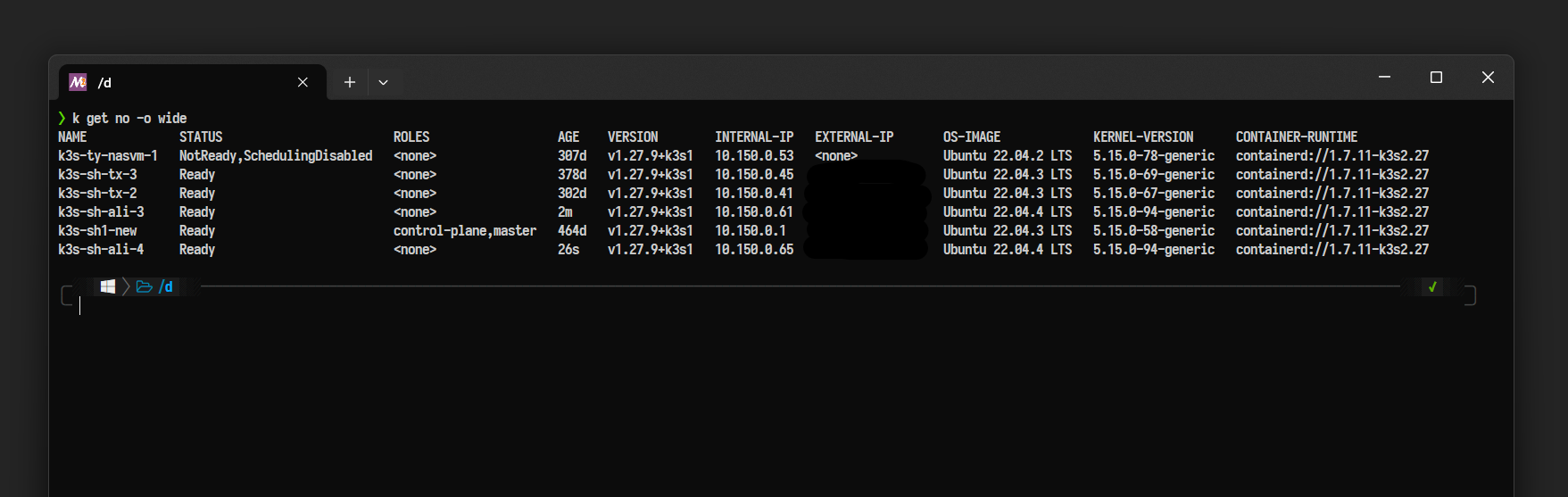
附一张 k get no -o wide 截图:
环境信息
K3s 版本
k3s version v1.27.9+k3s1 (2c249a39)
go version go1.20.12
已确认所有节点输出完全相同
节点 CPU 架构、操作系统和版本
Linux (节点名称) 5.15.0-58-generic #64-Ubuntu SMP Thu Jan 5 11:43:13 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
所有节点均为 Ubuntu 22.04,内核 5.15.0,仅小版本号不同
复现步骤
安装 K3s 的命令
server:
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_VERSION=v1.27.9+k3s1 INSTALL_K3S_MIRROR=cn sh -s - server --token=(token) --datastore-endpoint="mysql://root:(MySQL密码)@tcp(10.150.0.1:3306)/" --node-name k3s-sh1-new --node-external-ip (公网 IP) --advertise-address 10.150.0.1 --node-ip 10.150.0.1 --flannel-iface tun0 --disable traefik
agent(以 k3s-sh-tx-3 为例):
curl -sfL https://rancher-mirror.rancher.cn/k3s/k3s-install.sh | INSTALL_K3S_VERSION=v1.27.9+k3s1 INSTALL_K3S_MIRROR=cn sh -s - agent --server https://10.150.0.1:6443 --token=(token) --node-name k3s-sh-tx-3 --node-external-ip (公网 IP) --node-ip 10.150.0.45 --flannel-iface tun0
预期结果
在任意 agent 节点上,有
# curl http://127.0.0.1
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
实际结果
仅 server 节点能产生上面的输出,所有 agent 节点均 timeout。
排查步骤
基于以下几点:
- 80/443 以外的端口,各节点直接都能相互连通
- server 的 web 服务一直都没问题
- agent 的 web 服务在加入新节点之前也没问题
排除 ovpn 层的问题,排除 ingress-nginx 开始所有之后链路的问题,考虑 klipper、flannel、k3s 本身 的问题。
k describe service ingress-nginx-controller --namespace=ingress-nginx 的输出:
Name: ingress-nginx-controller
Namespace: ingress-nginx
Labels: app=ingress-nginx
app.kubernetes.io/component=controller
app.kubernetes.io/instance=ingress-nginx
app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=ingress-nginx
app.kubernetes.io/part-of=ingress-nginx
app.kubernetes.io/version=1.7.0
helm.sh/chart=ingress-nginx-4.6.0
Annotations: meta.helm.sh/release-name: ingress-nginx
meta.helm.sh/release-namespace: ingress-nginx
Selector: app.kubernetes.io/component=controller,app.kubernetes.io/instance=ingress-nginx,app.kubernetes.io/name=ingress-nginx
Type: LoadBalancer
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.43.102.77
IPs: 10.43.102.77
LoadBalancer Ingress: (所有机器的公网 IP)
Port: http 80/TCP
TargetPort: http/TCP
NodePort: http 32696/TCP
Endpoints: 10.42.0.58:80
Port: https 443/TCP
TargetPort: https/TCP
NodePort: https 30240/TCP
Endpoints: 10.42.0.58:443
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
根据 NodePort 访问 127.0.0.1:32696 结果相同,仍然只有 server 能返回 404。
但在 agent 节点上尝试重启 klipper、重启 k3s-agent,问题均未解决。重启 k3s server 可能能解决问题,但我目前希望先找找不重启 server 就能解决问题的方法。
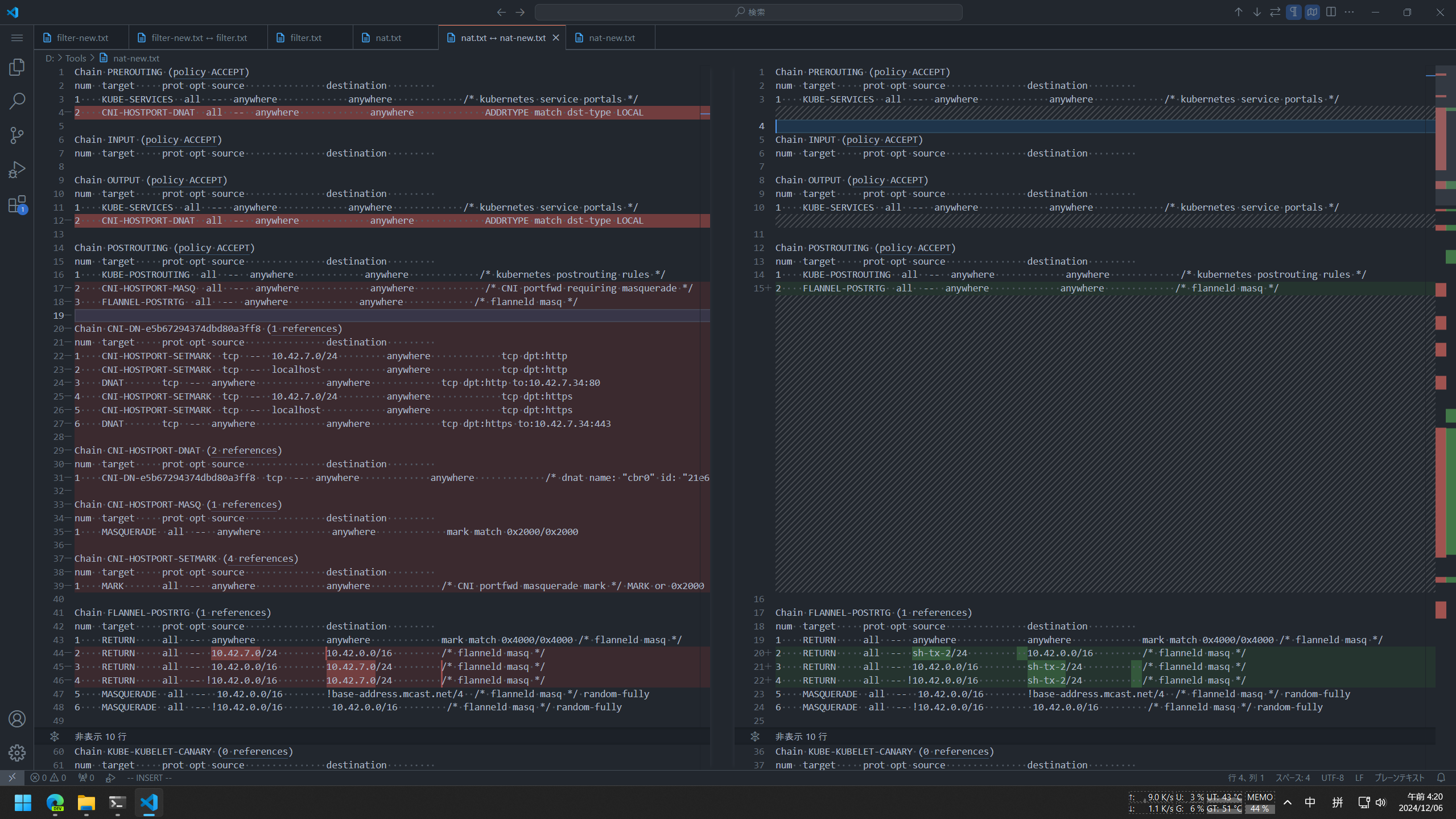
看过 iptables -L 但也没有什么头绪,只注意到 server 的 iptables 长度比 agent 多了近一倍,不知道是预期行为还是不太正常。
集群上有运行 Rancher,但四处看了看也没看到什么地方可能有问题。
由于出问题的地方卡在 ingress-nginx 之前,所以常用的容器内网络排查手段基本都起不到作用,目前想不到什么好的办法可以排查问题。如果有什么办法的话还请指教,在此先行致谢。如果有缺什么日志的话我都会补上。
日志
在 k3s-sh-ali-3(agent)上重新启动 klipper 的容器 log 全文:
+ trap exit TERM INT
+ BIN_DIR=/sbin
+ check_iptables_mode
+ set +e
+ lsmod
+ grep nf_tables
+ '[' 0 '=' 0 ]
+ mode=nft
+ set -e
+ info 'nft mode detected'
+ echo '[INFO] ' 'nft mode detected'
+ set_nft
+ ln -sf /sbin/xtables-nft-multi /sbin/iptables
nf_tables 266240 858 nft_limit,nft_chain_nat,nft_compat,nft_counter
nfnetlink 20480 5 nfnetlink_log,nf_conntrack_netlink,ip_set,nft_compat,nf_tables
libcrc32c 16384 5 nf_nat,nf_conntrack,nf_tables,btrfs,raid456
[INFO] nft mode detected
+ ln -sf /sbin/xtables-nft-multi /sbin/iptables-save
+ ln -sf /sbin/xtables-nft-multi /sbin/iptables-restore
+ ln -sf /sbin/xtables-nft-multi /sbin/ip6tables
+ start_proxy
+ echo 0.0.0.0/0
+ grep -Eq :
+ iptables -t filter -I FORWARD -s 0.0.0.0/0 -p TCP --dport 80 -j ACCEPT
+ echo 10.43.102.77
+ grep -Eq :
+ cat /proc/sys/net/ipv4/ip_forward
+ '[' 1 '==' 1 ]
+ iptables -t filter -A FORWARD -d 10.43.102.77/32 -p TCP --dport 80 -j DROP
+ iptables -t nat -I PREROUTING -p TCP --dport 80 -j DNAT --to 10.43.102.77:80
+ iptables -t nat -I POSTROUTING -d 10.43.102.77/32 -p TCP -j MASQUERADE
+ '[' '!' -e /pause ]
+ mkfifo /pause
重新启动 k3s-agent 的 journal 全文:
May 07 04:28:24 sh-ali-3 systemd[1]: Starting Lightweight Kubernetes...
░░ Subject: A start job for unit k3s-agent.service has begun execution
░░ Defined-By: systemd
░░ Support: http://www.ubuntu.com/support
░░
░░ A start job for unit k3s-agent.service has begun execution.
░░
░░ The job identifier is 11168.
May 07 04:28:24 sh-ali-3 sh[299968]: + /usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service
May 07 04:28:24 sh-ali-3 systemd[1]: k3s-agent.service: Found left-over process 287014 (containerd-shim) in control group while starting unit. Ignoring.
May 07 04:28:24 sh-ali-3 systemd[1]: This usually indicates unclean termination of a previous run, or service implementation deficiencies.
May 07 04:28:24 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:24+08:00" level=info msg="Starting k3s agent v1.27.9+k3s1 (2c249a39)"
May 07 04:28:24 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:24+08:00" level=info msg="Adding server to load balancer k3s-agent-load-balancer: 10.150.0.1:6443"
May 07 04:28:24 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:24+08:00" level=info msg="Running load balancer k3s-agent-load-balancer 127.0.0.1:6444 -> [10.150.0.1:6443] [default: 10.150.0.1:6443]"
May 07 04:28:24 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:24+08:00" level=warning msg="Cluster CA certificate is not trusted by the host CA bundle, but the token does not include a CA hash. Use the full token from the server's node-token file to enable Cluster CA validation."
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Module overlay was already loaded"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Module nf_conntrack was already loaded"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Module br_netfilter was already loaded"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Module iptable_nat was already loaded"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Module iptable_filter was already loaded"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Logging containerd to /var/lib/rancher/k3s/agent/containerd/containerd.log"
May 07 04:28:26 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:26+08:00" level=info msg="Running containerd -c /var/lib/rancher/k3s/agent/etc/containerd/config.toml -a /run/k3s/containerd/containerd.sock --state /run/k3s/containerd --root /var/lib/rancher/k3s/agent/containerd"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="containerd is now running"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Getting list of apiserver endpoints from server"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Updated load balancer k3s-agent-load-balancer default server address -> 10.150.0.1:6443"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Connecting to proxy" url="wss://10.150.0.1:6443/v1-k3s/connect"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Running kubelet --address=0.0.0.0 --allowed-unsafe-sysctls=net.ipv4.ip_forward,net.ipv6.conf.all.forwarding --anonymous-auth=false --authentication-token-webhook=true --authorization-mode=Webhook --cgroup-driver=systemd --client-ca-file=/var/lib/rancher/k3s/agent/client-ca.crt --cloud-provider=external --cluster-dns=10.43.0.10 --cluster-domain=cluster.local --container-runtime-endpoint=unix:///run/k3s/containerd/containerd.sock --containerd=/run/k3s/containerd/containerd.sock --eviction-hard=imagefs.available<5%,nodefs.available<5% --eviction-minimum-reclaim=imagefs.available=10%,nodefs.available=10% --fail-swap-on=false --feature-gates=CloudDualStackNodeIPs=true --healthz-bind-address=127.0.0.1 --hostname-override=k3s-sh-ali-3 --kubeconfig=/var/lib/rancher/k3s/agent/kubelet.kubeconfig --node-ip=10.150.0.61 --node-labels= --pod-infra-container-image=rancher/mirrored-pause:3.6 --pod-manifest-path=/var/lib/rancher/k3s/agent/pod-manifests --read-only-port=0 --resolv-conf=/run/systemd/resolve/resolv.conf --serialize-image-pulls=false --tls-cert-file=/var/lib/rancher/k3s/agent/serving-kubelet.crt --tls-private-key-file=/var/lib/rancher/k3s/agent/serving-kubelet.key"
May 07 04:28:27 sh-ali-3 k3s[299972]: Flag --cloud-provider has been deprecated, will be removed in 1.25 or later, in favor of removing cloud provider code from Kubelet.
May 07 04:28:27 sh-ali-3 k3s[299972]: Flag --containerd has been deprecated, This is a cadvisor flag that was mistakenly registered with the Kubelet. Due to legacy concerns, it will follow the standard CLI deprecation timeline before being removed.
May 07 04:28:27 sh-ali-3 k3s[299972]: Flag --pod-infra-container-image has been deprecated, will be removed in a future release. Image garbage collector will get sandbox image information from CRI.
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.791764 299972 server.go:198] "--pod-infra-container-image will not be pruned by the image garbage collector in kubelet and should also be set in the remote runtime"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.794560 299972 server.go:410] "Kubelet version" kubeletVersion="v1.27.9+k3s1"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.795072 299972 server.go:412] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.803072 299972 dynamic_cafile_content.go:157] "Starting controller" name="client-ca-bundle::/var/lib/rancher/k3s/agent/client-ca.crt"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.803857 299972 server.go:657] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.804819 299972 container_manager_linux.go:265] "Container manager verified user specified cgroup-root exists" cgroupRoot=[]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.805357 299972 container_manager_linux.go:270] "Creating Container Manager object based on Node Config" nodeConfig={RuntimeCgroupsName: SystemCgroupsName: KubeletCgroupsName: KubeletOOMScoreAdj:-999 ContainerRuntime: CgroupsPerQOS:true CgroupRoot:/ CgroupDriver:systemd KubeletRootDir:/var/lib/kubelet ProtectKernelDefaults:false NodeAllocatableConfig:{KubeReservedCgroupName: SystemReservedCgroupName: ReservedSystemCPUs: EnforceNodeAllocatable:map[pods:{}] KubeReserved:map[] SystemReserved:map[] HardEvictionThresholds:[{Signal:imagefs.available Operator:LessThan Value:{Quantity:<nil> Percentage:0.05} GracePeriod:0s MinReclaim:<nil>} {Signal:nodefs.available Operator:LessThan Value:{Quantity:<nil> Percentage:0.05} GracePeriod:0s MinReclaim:<nil>}]} QOSReserved:map[] CPUManagerPolicy:none CPUManagerPolicyOptions:map[] TopologyManagerScope:container CPUManagerReconcilePeriod:10s ExperimentalMemoryManagerPolicy:None ExperimentalMemoryManagerReservedMemory:[] PodPidsLimit:-1 EnforceCPULimits:true CPUCFSQuotaPeriod:100ms TopologyManagerPolicy:none ExperimentalTopologyManagerPolicyOptions:map[]}
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.805843 299972 topology_manager.go:136] "Creating topology manager with policy per scope" topologyPolicyName="none" topologyScopeName="container"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.806178 299972 container_manager_linux.go:301] "Creating device plugin manager"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.806505 299972 state_mem.go:36] "Initialized new in-memory state store"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.810782 299972 kubelet.go:405] "Attempting to sync node with API server"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.810809 299972 kubelet.go:298] "Adding static pod path" path="/var/lib/rancher/k3s/agent/pod-manifests"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.810843 299972 kubelet.go:309] "Adding apiserver pod source"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.810865 299972 apiserver.go:42] "Waiting for node sync before watching apiserver pods"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.812460 299972 kuberuntime_manager.go:257] "Container runtime initialized" containerRuntime="containerd" version="v1.7.11-k3s2.27" apiVersion="v1"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.813388 299972 server.go:1163] "Started kubelet"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Annotations and labels have already set on node: k3s-sh-ali-3"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.816044 299972 fs_resource_analyzer.go:67] "Starting FS ResourceAnalyzer"
May 07 04:28:27 sh-ali-3 k3s[299972]: E0507 04:28:27.818733 299972 cri_stats_provider.go:455] "Failed to get the info of the filesystem with mountpoint" err="unable to find data in memory cache" mountpoint="/var/lib/rancher/k3s/agent/containerd/io.containerd.snapshotter.v1.overlayfs"
May 07 04:28:27 sh-ali-3 k3s[299972]: E0507 04:28:27.819186 299972 kubelet.go:1400] "Image garbage collection failed once. Stats initialization may not have completed yet" err="invalid capacity 0 on image filesystem"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.825159 299972 server.go:162] "Starting to listen" address="0.0.0.0" port=10250
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.826733 299972 volume_manager.go:284] "Starting Kubelet Volume Manager"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.827234 299972 server.go:461] "Adding debug handlers to kubelet server"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.829076 299972 ratelimit.go:65] "Setting rate limiting for podresources endpoint" qps=100 burstTokens=10
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.830763 299972 desired_state_of_world_populator.go:145] "Desired state populator starts to run"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.834627 299972 kubelet_network_linux.go:63] "Initialized iptables rules." protocol=IPv4
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.836823 299972 kubelet_network_linux.go:63] "Initialized iptables rules." protocol=IPv6
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.836880 299972 status_manager.go:207] "Starting to sync pod status with apiserver"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.836909 299972 kubelet.go:2257] "Starting kubelet main sync loop"
May 07 04:28:27 sh-ali-3 k3s[299972]: E0507 04:28:27.836999 299972 kubelet.go:2281] "Skipping pod synchronization" err="[container runtime status check may not have completed yet, PLEG is not healthy: pleg has yet to be successful]"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Starting flannel with backend vxlan"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="Flannel found PodCIDR assigned for node k3s-sh-ali-3"
May 07 04:28:27 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:27+08:00" level=info msg="The interface tun0 with ipv4 address 10.150.0.61 will be used by flannel"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.899150 299972 kube.go:145] Waiting 10m0s for node controller to sync
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.901348 299972 kube.go:489] Starting kube subnet manager
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.910909 299972 cpu_manager.go:214] "Starting CPU manager" policy="none"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.911321 299972 cpu_manager.go:215] "Reconciling" reconcilePeriod="10s"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.911712 299972 state_mem.go:36] "Initialized new in-memory state store"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.912293 299972 state_mem.go:88] "Updated default CPUSet" cpuSet=""
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.912791 299972 state_mem.go:96] "Updated CPUSet assignments" assignments=map[]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.913061 299972 policy_none.go:49] "None policy: Start"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.915077 299972 memory_manager.go:169] "Starting memorymanager" policy="None"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.915124 299972 state_mem.go:35] "Initializing new in-memory state store"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.915438 299972 state_mem.go:75] "Updated machine memory state"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.920669 299972 manager.go:471] "Failed to read data from checkpoint" checkpoint="kubelet_internal_checkpoint" err="checkpoint is not found"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.923338 299972 plugin_manager.go:118] "Starting Kubelet Plugin Manager"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.927915 299972 kubelet_node_status.go:70] "Attempting to register node" node="k3s-sh-ali-3"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944304 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.1.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944383 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.2.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944396 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.7.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944424 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.4.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944434 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.0.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.944442 299972 kube.go:510] Creating the node lease for IPv4. This is the n.Spec.PodCIDRs: [10.42.3.0/24]
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.954202 299972 kubelet_node_status.go:108] "Node was previously registered" node="k3s-sh-ali-3"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.954368 299972 kubelet_node_status.go:73] "Successfully registered node" node="k3s-sh-ali-3"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.972785 299972 kuberuntime_manager.go:1460] "Updating runtime config through cri with podcidr" CIDR="10.42.1.0/24"
May 07 04:28:27 sh-ali-3 k3s[299972]: I0507 04:28:27.973758 299972 kubelet_network.go:61] "Updating Pod CIDR" originalPodCIDR="" newPodCIDR="10.42.1.0/24"
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="Starting the netpol controller version v2.0.0-20230925161250-364f994b140b, built on 2023-12-27T15:00:35Z, go1.20.12"
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="k3s agent is up and running"
May 07 04:28:28 sh-ali-3 systemd[1]: Started Lightweight Kubernetes.
░░ Subject: A start job for unit k3s-agent.service has finished successfully
░░ Defined-By: systemd
░░ Support: http://www.ubuntu.com/support
░░
░░ A start job for unit k3s-agent.service has finished successfully.
░░
░░ The job identifier is 11168.
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.018872 299972 network_policy_controller.go:164] Starting network policy controller
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.056334 299972 network_policy_controller.go:176] Starting network policy controller full sync goroutine
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="Running kube-proxy --cluster-cidr=10.42.0.0/16 --conntrack-max-per-core=0 --conntrack-tcp-timeout-close-wait=0s --conntrack-tcp-timeout-established=0s --healthz-bind-address=127.0.0.1 --hostname-override=k3s-sh-ali-3 --kubeconfig=/var/lib/rancher/k3s/agent/kubeproxy.kubeconfig --proxy-mode=iptables"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.338067 299972 server.go:226] "Warning, all flags other than --config, --write-config-to, and --cleanup are deprecated, please begin using a config file ASAP"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.367849 299972 node.go:141] Successfully retrieved node IP: 10.150.0.61
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.367909 299972 server_others.go:110] "Detected node IP" address="10.150.0.61"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.374106 299972 server_others.go:192] "Using iptables Proxier"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.374142 299972 server_others.go:199] "kube-proxy running in dual-stack mode" ipFamily=IPv4
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.374154 299972 server_others.go:200] "Creating dualStackProxier for iptables"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.374187 299972 server_others.go:484] "Detect-local-mode set to ClusterCIDR, but no IPv6 cluster CIDR defined, defaulting to no-op detect-local for IPv6"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.374220 299972 proxier.go:253] "Setting route_localnet=1 to allow node-ports on localhost; to change this either disable iptables.localhostNodePorts (--iptables-localhost-nodeports) or set nodePortAddresses (--nodeport-addresses) to filter loopback addresses"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.375159 299972 server.go:658] "Version info" version="v1.27.9+k3s1"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.375211 299972 server.go:660] "Golang settings" GOGC="" GOMAXPROCS="" GOTRACEBACK=""
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.378127 299972 config.go:188] "Starting service config controller"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.378173 299972 shared_informer.go:311] Waiting for caches to sync for service config
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.378208 299972 config.go:97] "Starting endpoint slice config controller"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.378215 299972 shared_informer.go:311] Waiting for caches to sync for endpoint slice config
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.379184 299972 config.go:315] "Starting node config controller"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.379225 299972 shared_informer.go:311] Waiting for caches to sync for node config
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.478791 299972 shared_informer.go:318] Caches are synced for service config
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.478791 299972 shared_informer.go:318] Caches are synced for endpoint slice config
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.479284 299972 shared_informer.go:318] Caches are synced for node config
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="Tunnel authorizer set Kubelet Port 10250"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.812187 299972 apiserver.go:52] "Watching apiserver"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.824903 299972 topology_manager.go:212] "Topology Admit Handler" podUID=8323c327-8d8e-4435-8254-f7357cd7fd49 podNamespace="kube-system" podName="svclb-ingress-nginx-controller-1146ef43-7k9lq"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.831094 299972 desired_state_of_world_populator.go:153] "Finished populating initial desired state of world"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.835205 299972 reconciler.go:41] "Reconciler: start to sync state"
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.899775 299972 kube.go:152] Node controller sync successful
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.899896 299972 vxlan.go:141] VXLAN config: VNI=1 Port=0 GBP=false Learning=false DirectRouting=false
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="Wrote flannel subnet file to /run/flannel/subnet.env"
May 07 04:28:28 sh-ali-3 k3s[299972]: time="2024-05-07T04:28:28+08:00" level=info msg="Running flannel backend."
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.945101 299972 iptables.go:290] generated 3 rules
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.945502 299972 vxlan_network.go:65] watching for new subnet leases
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.945947 299972 subnet.go:159] Batch elem [0] is { lease.Event{Type:0, Lease:lease.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xa2a0200, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:lease.LeaseAttrs{PublicIP:0xa960041, PublicIPv6:(*ip.IP6)(nil), BackendType:"vxlan", BackendData:json.RawMessage{0x7b, 0x22, 0x56, 0x4e, 0x49, 0x22, 0x3a, 0x31, 0x2c, 0x22, 0x56, 0x74, 0x65, 0x70, 0x4d, 0x41, 0x43, 0x22, 0x3a, 0x22, 0x31, 0x61, 0x3a, 0x36, 0x31, 0x3a, 0x66, 0x38, 0x3a, 0x31, 0x39, 0x3a, 0x33, 0x65, 0x3a, 0x62, 0x36, 0x22, 0x7d}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.946658 299972 subnet.go:159] Batch elem [0] is { lease.Event{Type:0, Lease:lease.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xa2a0700, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:lease.LeaseAttrs{PublicIP:0xa960029, PublicIPv6:(*ip.IP6)(nil), BackendType:"vxlan", BackendData:json.RawMessage{0x7b, 0x22, 0x56, 0x4e, 0x49, 0x22, 0x3a, 0x31, 0x2c, 0x22, 0x56, 0x74, 0x65, 0x70, 0x4d, 0x41, 0x43, 0x22, 0x3a, 0x22, 0x61, 0x61, 0x3a, 0x30, 0x32, 0x3a, 0x63, 0x35, 0x3a, 0x63, 0x36, 0x3a, 0x64, 0x31, 0x3a, 0x38, 0x38, 0x22, 0x7d}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.946733 299972 subnet.go:159] Batch elem [0] is { lease.Event{Type:0, Lease:lease.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xa2a0400, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:lease.LeaseAttrs{PublicIP:0xa96002d, PublicIPv6:(*ip.IP6)(nil), BackendType:"vxlan", BackendData:json.RawMessage{0x7b, 0x22, 0x56, 0x4e, 0x49, 0x22, 0x3a, 0x31, 0x2c, 0x22, 0x56, 0x74, 0x65, 0x70, 0x4d, 0x41, 0x43, 0x22, 0x3a, 0x22, 0x61, 0x61, 0x3a, 0x30, 0x31, 0x3a, 0x39, 0x34, 0x3a, 0x32, 0x31, 0x3a, 0x63, 0x30, 0x3a, 0x33, 0x35, 0x22, 0x7d}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.947333 299972 subnet.go:159] Batch elem [0] is { lease.Event{Type:0, Lease:lease.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xa2a0000, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:lease.LeaseAttrs{PublicIP:0xa960001, PublicIPv6:(*ip.IP6)(nil), BackendType:"vxlan", BackendData:json.RawMessage{0x7b, 0x22, 0x56, 0x4e, 0x49, 0x22, 0x3a, 0x31, 0x2c, 0x22, 0x56, 0x74, 0x65, 0x70, 0x4d, 0x41, 0x43, 0x22, 0x3a, 0x22, 0x65, 0x61, 0x3a, 0x65, 0x33, 0x3a, 0x31, 0x32, 0x3a, 0x38, 0x62, 0x3a, 0x66, 0x39, 0x3a, 0x37, 0x32, 0x22, 0x7d}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.947762 299972 subnet.go:159] Batch elem [0] is { lease.Event{Type:0, Lease:lease.Lease{EnableIPv4:true, EnableIPv6:false, Subnet:ip.IP4Net{IP:0xa2a0300, PrefixLen:0x18}, IPv6Subnet:ip.IP6Net{IP:(*ip.IP6)(nil), PrefixLen:0x0}, Attrs:lease.LeaseAttrs{PublicIP:0xa960035, PublicIPv6:(*ip.IP6)(nil), BackendType:"vxlan", BackendData:json.RawMessage{0x7b, 0x22, 0x56, 0x4e, 0x49, 0x22, 0x3a, 0x31, 0x2c, 0x22, 0x56, 0x74, 0x65, 0x70, 0x4d, 0x41, 0x43, 0x22, 0x3a, 0x22, 0x65, 0x61, 0x3a, 0x36, 0x61, 0x3a, 0x39, 0x31, 0x3a, 0x64, 0x31, 0x3a, 0x64, 0x30, 0x3a, 0x34, 0x35, 0x22, 0x7d}, BackendV6Data:json.RawMessage(nil)}, Expiration:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Asof:0}} }
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.949349 299972 iptables.go:290] generated 7 rules
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.972555 299972 iptables.go:283] bootstrap done
May 07 04:28:28 sh-ali-3 k3s[299972]: I0507 04:28:28.989370 299972 iptables.go:283] bootstrap done