Tower
2022 年8 月 17 日 07:13
1
环境信息:
集群配置:
问题描述:
查看磁盘空间是充足的,请指教
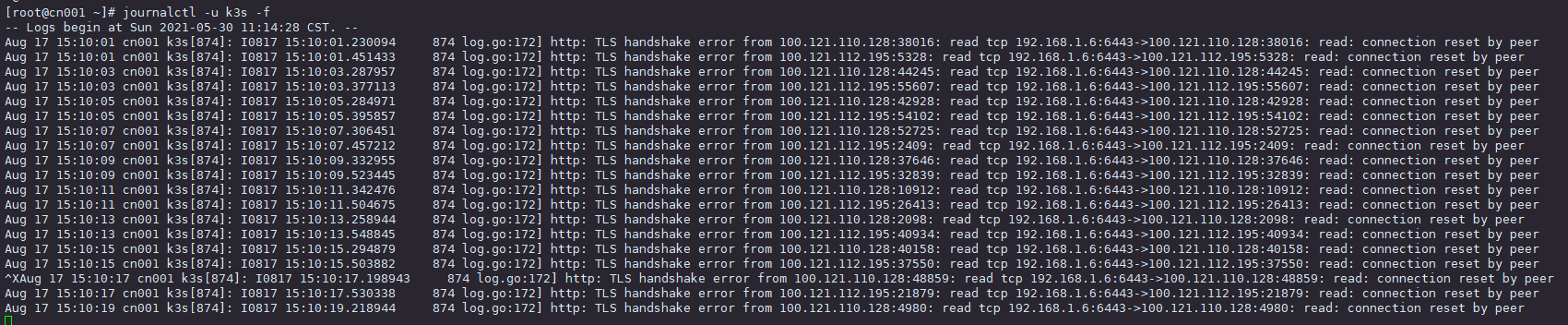
重启服务器,整个集群恢复正常访问发现 大量异常 http: TLS handshake error from read: connection reset by peer
前几天更换了rancher 的 SSL 证书,可rancher pod 都正常
好像是这个 issueshttps://github.com/kubernetes/kubernetes/issues/60987 )
[https://github.com/kubernetes/kubernetes/pull/95301 ]
2021年3月13日 修复代码,而 1.18.20 是在这个之后才发布的,按道理不应该出现问题才对
不确定你的部署架构。按照我的理解,如果k3s作为local集群,并不需要阿里云slb暴露k3s的6443端口。
另外,rancher有自己的一套证书体系,k3s也是有自己的证书体系,可以确认一下k3s的证书状态。
如果你提到kubectl连接k3s无法访问,最好能给出一个输出结果,具体提示什么信息。
如果方便可以额外给出这个命令的返回信息:
kubectl --insecure-skip-tls-verify get secret -n kube-system k3s-serving -o jsonpath='{.data.tls\.crt}' | base64 -d | openssl x509 -noout -text
Tower
2022 年8 月 18 日 02:17
3
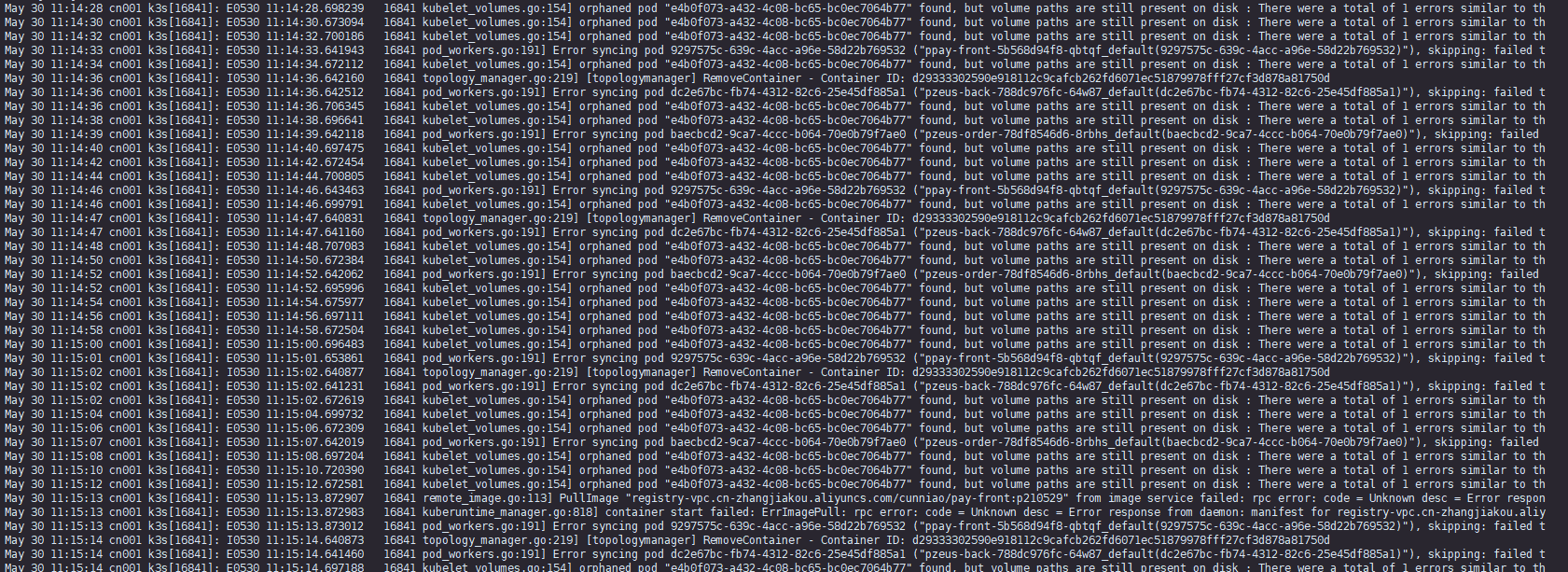
就是local 集群使用,关闭6443端口,SSL 错误没有了Orphaned pod found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them.
不知道啥情况,看issue k8s 1.8.20 的版本应该修复了才对,可还是出现了,重启k3s都没有,重启服务器就可以恢复正常
Tower
2022 年8 月 18 日 02:37
4
opened 05:04PM - 09 Mar 18 UTC
closed 07:15AM - 17 Mar 21 UTC
sig/storage
sig/node
needs-triage
<!-- This form is for bug reports and feature requests ONLY!
If you're looki… ng for help check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
-->
**Is this a BUG REPORT or FEATURE REQUEST?**:
BUG
**What happened**:
Kubelet is periodically going into an error state and causing errors with our storage layer (ceph, shared filesystem). Upon cleaning out the orphaned pod directory things eventually right themselves.
* Workaround: `rmdir /var/lib/kubelet/pods/*/volumes/*rook/*`
**What you expected to happen**:
Kubelet should intelligently deal with orphaned pods. Cleaning a stale directory manually should not be required.
**How to reproduce it (as minimally and precisely as possible)**:
Using rook-0.7.0 (this isn't a rook problem as far as I can tell but this is how we're reproducing):
kubectl create -f rook-operator.yaml
kubectl create -f rook-cluster.yaml
kubectl create -f rook-filesystem.yaml
Mount/write to the shared filesystem and monitor /var/log/messages for the following:
`
kubelet: E0309 16:46:30.429770 3112 kubelet_volumes.go:128] Orphaned pod "2815f27a-219b-11e8-8a2a-ec0d9a3a445a" found, but volume paths are still present on disk : There were a total of 1 errors similar to this. Turn up verbosity to see them.
`
**Anything else we need to know?**:
This looks identical to the following: https://github.com/kubernetes/kubernetes/issues/45464 but for a different plugin.
**Environment**:
- Kubernetes version (use `kubectl version`):
`
Client Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.3", GitCommit:"d2835416544f298c919e2ead3be3d0864b52323b", GitTreeState:"clean", BuildDate:"2018-02-07T12:22:21Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"9", GitVersion:"v1.9.3", GitCommit:"d2835416544f298c919e2ead3be3d0864b52323b", GitTreeState:"clean", BuildDate:"2018-02-07T11:55:20Z", GoVersion:"go1.9.2", Compiler:"gc", Platform:"linux/amd64"}
`
- Cloud provider or hardware configuration:
Bare-metal private cloud
- OS (e.g. from /etc/os-release):
Red Hat Enterprise Linux Server release 7.4 (Maipo)
- Kernel (e.g. `uname -a`):
Linux 4.4.115-1.el7.elrepo.x86_64 #1 SMP Sat Feb 3 20:11:41 EST 2018 x86_64 x86_64 x86_64 GNU/Linux
- Install tools:
kubeadm
原来是只修复仅删除空目录情况,我的挂载啥情况导致也不清楚
集群运行 700多天就出现过这一次