- rancher 版本:v2.5.9
- kubernetes 版本:1.20.8
- coredns:mirrored-coredns-coredns:1.8.0
- flannel: coreos-flannel:v0.13.0-rancher1
现象:
-
集群内pod访问pod ip无异常
-
集群内pod访问 service ip无异常
-
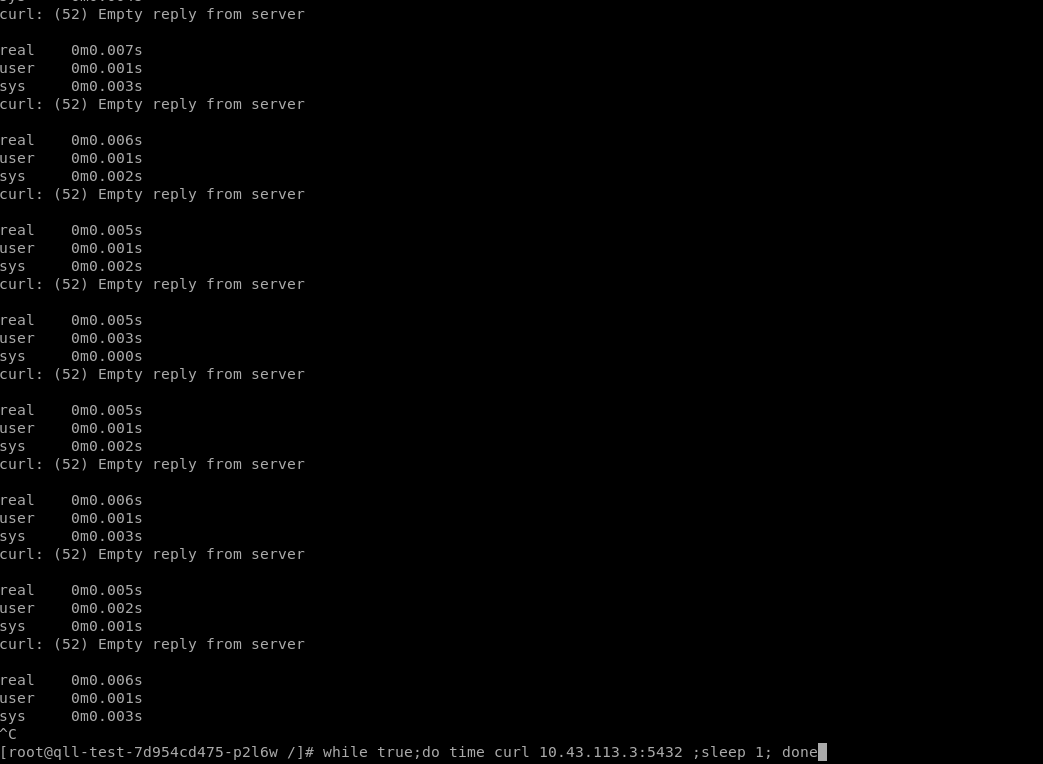
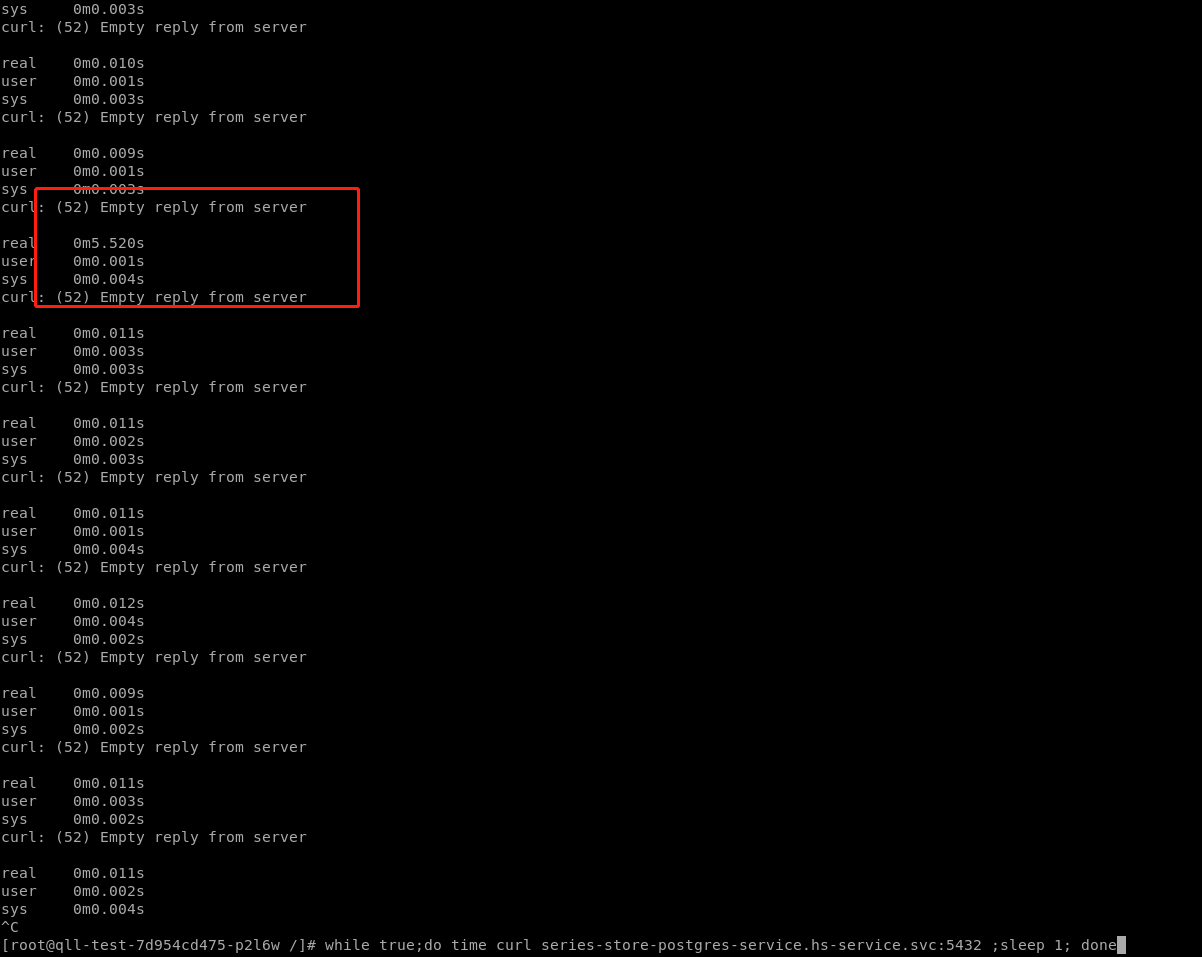
集群内pod访问service dns name偶发异常(相同和不同node节点上的服务都会异常)
-
集群内pod访问集群外部服务偶发异常(图没有保留下来)
补充:
pod中通过dig 和 nslookup指定kube-dns的service ip解析域名,发现会卡在coredns解析部分;
node通过dig 和 nslookup 指定kube-dns的service ip解析域名无异常
集群进行过(搬迁)重启,某一次重启之后就成这样了,重启前无异常。
异常之后还进行过几次重启但是都没有解决问题。中间将kube-proxy的proxy-mode从iptables修改为了ipvs,也并没有解决。使用iptables [-tnat] --flush清理过iptables规则,并重启了kubelet也没有解决。
请问下有人遇到过类似情况或者处理思路吗?(或者搬迁过程中网卡/网线松动?这部分会尝试重插一下)