问题描述
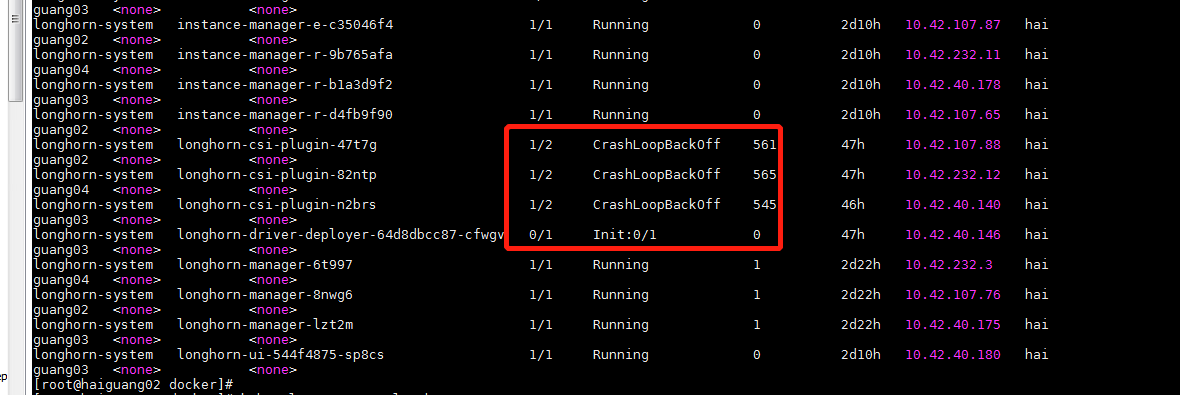
所有节点CSI处于CrashLoopBackOff状态,导致longhorn-driver-deployer无法初始化
日志
日志
[root@haiguang02 sysctl.d]# kubectl logs longhorn-csi-plugin-n2brs -n longhorn-system longhorn-csi-plugin
2022/07/01 11:11:21 proto: duplicate proto type registered: VersionResponse
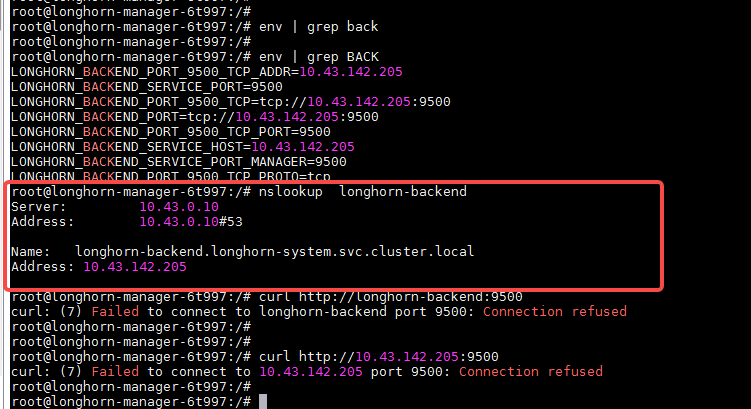
time="2022-07-01T11:11:21Z" level=info msg="CSI Driver: driver.longhorn.io version: v1.2.3, manager URL http://longhorn-backend:9500/v1"
time="2022-07-01T11:11:22Z" level=fatal msg="Error starting CSI manager: Failed to initialize Longhorn API client: Get \"http://longhorn-backend:9500/v1\": dial tcp 10.43.142.205:9500: connect: connection refused"
[root@haiguang02 sysctl.d]# kubectl logs longhorn-csi-plugin-n2brs -n longhorn-system
error: a container name must be specified for pod longhorn-csi-plugin-n2brs, choose one of: [node-driver-registrar longhorn-csi-plugin]
[root@haiguang02 sysctl.d]# kubectl logs longhorn-csi-plugin-n2brs -n longhorn-system node-driver-registrar
I0629 03:14:00.793522 36971 main.go:164] Version: v2.3.0
I0629 03:14:00.793589 36971 main.go:165] Running node-driver-registrar in mode=registration
I0629 03:14:00.811652 36971 main.go:189] Attempting to open a gRPC connection with: "/csi/csi.sock"
W0629 03:14:10.811903 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:14:20.811974 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:14:30.812360 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:14:40.812174 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:14:50.812674 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:00.811738 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:10.811938 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:20.812342 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:30.812800 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:40.812045 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:15:50.812235 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
W0629 03:16:00.811850 36971 connection.go:173] Still connecting to unix:///csi/csi.sock
环境信息
- Longhorn 版本:
- 安装方法 (e.g. Rancher Catalog App/Helm/Kubectl): Rancher Catalog App
- Kubernetes 发行版 (e.g. RKE/K3s/EKS/OpenShift) 和版本: RKE
- 集群管理节点个数: 3
- 集群 worker 节点数: 1
- Node 配置
- 操作系统类型和版本: centos 7.8
- 每个节点的CPU: 104
- 每个节点的内存:256
- 磁盘类型(e.g. SSD/NVMe): SSD
- 节点间网络带宽::10G
- 底层基础设施 (e.g. on AWS/GCE, EKS/GKE, VMWare/KVM, Baremetal): 物理机
- 集群中Longhorn卷的个数: 10