各位大佬,我现在是RKE2集群(v1.24.10+rke2r1)导入到Rancher-UI(v2.6.10)里进行管理的,在UI上我部署的这个Monitoring(Chart: Monitoring (100.2.0+up40.1.2))在集群中进行监控,前期数据量少运行还可以,但是随着监控的服务逐渐增多,现在Prometheus时常OOMKilled,内存已经加到8G了,还是不够。
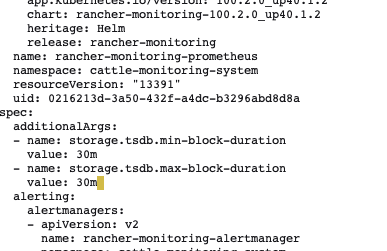
查了一下说可以修改 --storage.tsdb.min-block-duration 和 --storage.tsdb.max-block-duration 缩短写盘时间可以缓解,但是找不到哪里可以进行修改,直接修改Prometheus的 StatefulSets 启动命令也无法生效,会被默认的启动参数覆盖掉,Monitoring 的配置YAML 里也找不到地方哪里可以改,请问哪位大佬知道啊?

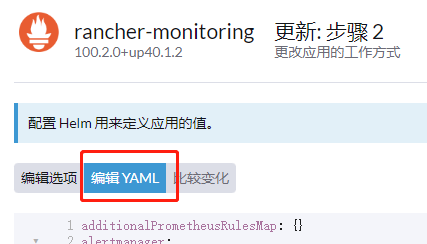
方案可行,但是需要在2个地方都修改才可以成功。
第一个地方:

第二个地方:
kubectl edit prometheus rancher-monitoring-prometheus -n cattle-monitoring-system
这两个地方都修改并完成部署后,则可以看到修改成功了。

虽然通过上述方法,能够成功修改 --storage.tsdb.min-block-duration 和 --storage.tsdb.max-block-duration ,但并未解决我的 prometheus OOMkilled 问题。
再次排查导致我 prometheus OOMkilled 的原因是由于 ingress-nginx 收集的指标太多造成的,可以通过
sort_desc(sum(scrape_samples_scraped) by (job))
看出来。

临时解决办法:
删除对 ingress 指标的收集:
监控->Monitors->ServiceMonitor,在 kube-system 命名空间,找到 rancher-monitoring-ingress-nginx ,删除即可。
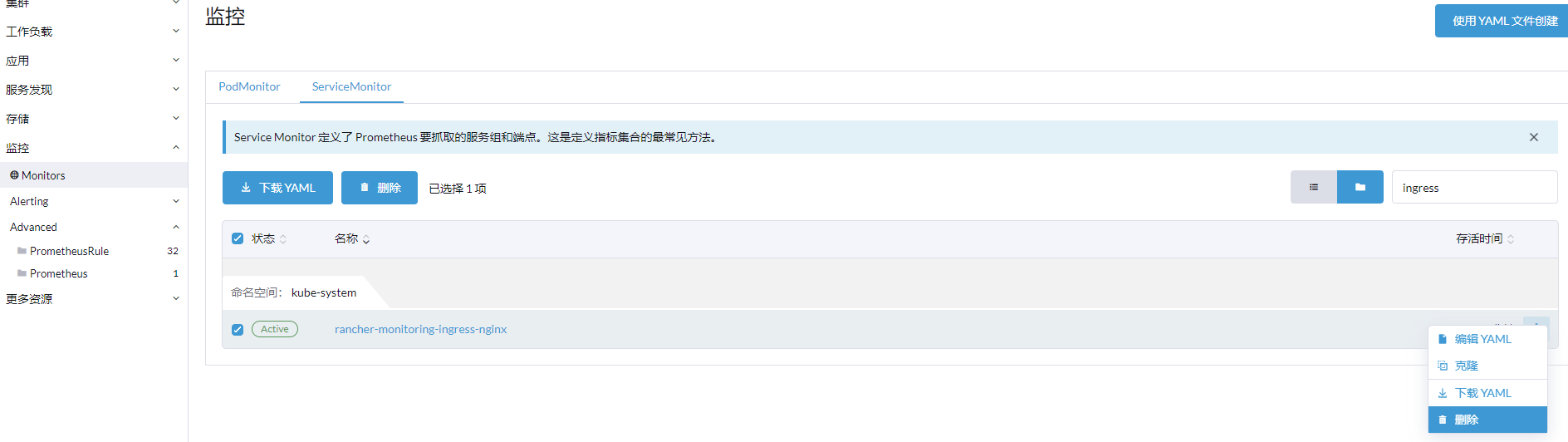
删除之后,即可看到内存明显的下降。
问题暂时解决了,但是不收集 ingress 似乎也不太行,最终解决办法还需要继续研究。
resources.limits 有调了吧。
也可以尝试下将刮取间隔设长一点
limits 已经调到 8196Mi 了。
Prometheus抓取时间间隔为默认的 1m ,在ingress的ServiceMonitor中没有发现有 interval 的标志,是否意味着ingress的抓取时间间隔也是 1m 呢?