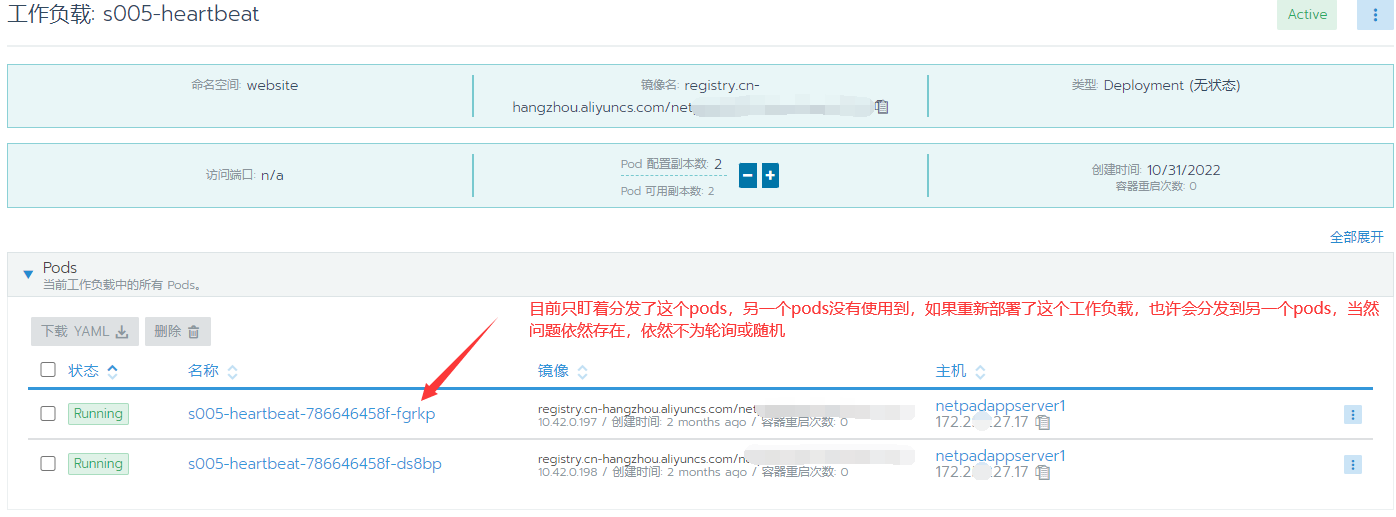
rancher版本v2.5.7。当前集群的某个工作负载的pods副本数大于1时。pods的分发策略不是轮询或随机分发,只会死盯着其中一个pods分发,其他的pods无法接收到任何请求。我去查询这个工作负载创建好后自动生成的服务发现。其中spec.sessionAffinity: None,即应该是默认轮询分发。目前集群中的工作负载都是这个情况,只要pods大于1了就死盯着其中一个pods分发请求,其他不会分发到。这个问题,找不到原因,找不到相关案例,希望大家指点下。
工作负载:
pods:
服务发现:
这个服务发现的yaml文件:
apiVersion: v1
kind: Service
metadata:
annotations:
field.cattle.io/ipAddresses: “null”
field.cattle.io/targetDnsRecordIds: “null”
field.cattle.io/targetWorkloadIds: ‘[“deployment:website:s005-heartbeat”]’
workload.cattle.io/targetWorkloadIdNoop: “true”
workload.cattle.io/workloadPortBased: “true”
creationTimestamp: “2022-10-31T09:40:51Z”
labels:
cattle.io/creator: norman
managedFields:
- apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
.: {}
f:field.cattle.io/targetWorkloadIds: {}
f:workload.cattle.io/targetWorkloadIdNoop: {}
f:workload.cattle.io/workloadPortBased: {}
f:labels:
.: {}
f:cattle.io/creator: {}
f:ownerReferences:
.: {}
k:{“uid”:“12439c07-c37e-411d-8bde-f5e45e6934a9”}:
.: {}
f:apiVersion: {}
f:controller: {}
f:kind: {}
f:name: {}
f:uid: {}
f:spec:
f:ports:
.: {}
k:{“port”:3000,“protocol”:“TCP”}:
.: {}
f:name: {}
f:port: {}
f:protocol: {}
f:targetPort: {}
f:selector:
.: {}
f:workload.user.cattle.io/workloadselector: {}
f:type: {}
manager: rancher
operation: Update
time: “2022-10-31T09:40:51Z” - apiVersion: v1
fieldsType: FieldsV1
fieldsV1:
f:metadata:
f:annotations:
f:field.cattle.io/ipAddresses: {}
f:field.cattle.io/targetDnsRecordIds: {}
f:spec:
f:sessionAffinity: {}
manager: Go-http-client
operation: Update
time: “2023-12-10T12:11:33Z”
name: s005-heartbeat
namespace: website
ownerReferences: - apiVersion: apps/v1beta2
controller: true
kind: deployment
name: s005-heartbeat
uid: 12439c07-c37e-411d-8bde-f5e45e6934a9
resourceVersion: “358515398”
uid: 94b812ea-2fc6-44d9-9f6e-7fac93c770ad
spec:
clusterIP: 10.43.232.76
clusterIPs: - 10.43.232.76
ports: - name: 3000tcp02
port: 3000
protocol: TCP
targetPort: 3000
selector:
workload.user.cattle.io/workloadselector: deployment-website-s005-heartbeat
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}