查看rancher 容器日志
[ERROR] [updateClusterHealth] Failed to update cluster [c-6z88d]: Operation cannot be fulfilled on clusters.management.cattle.io "c-6z88d": the object has been modified; please apply your changes to the latest version and try again
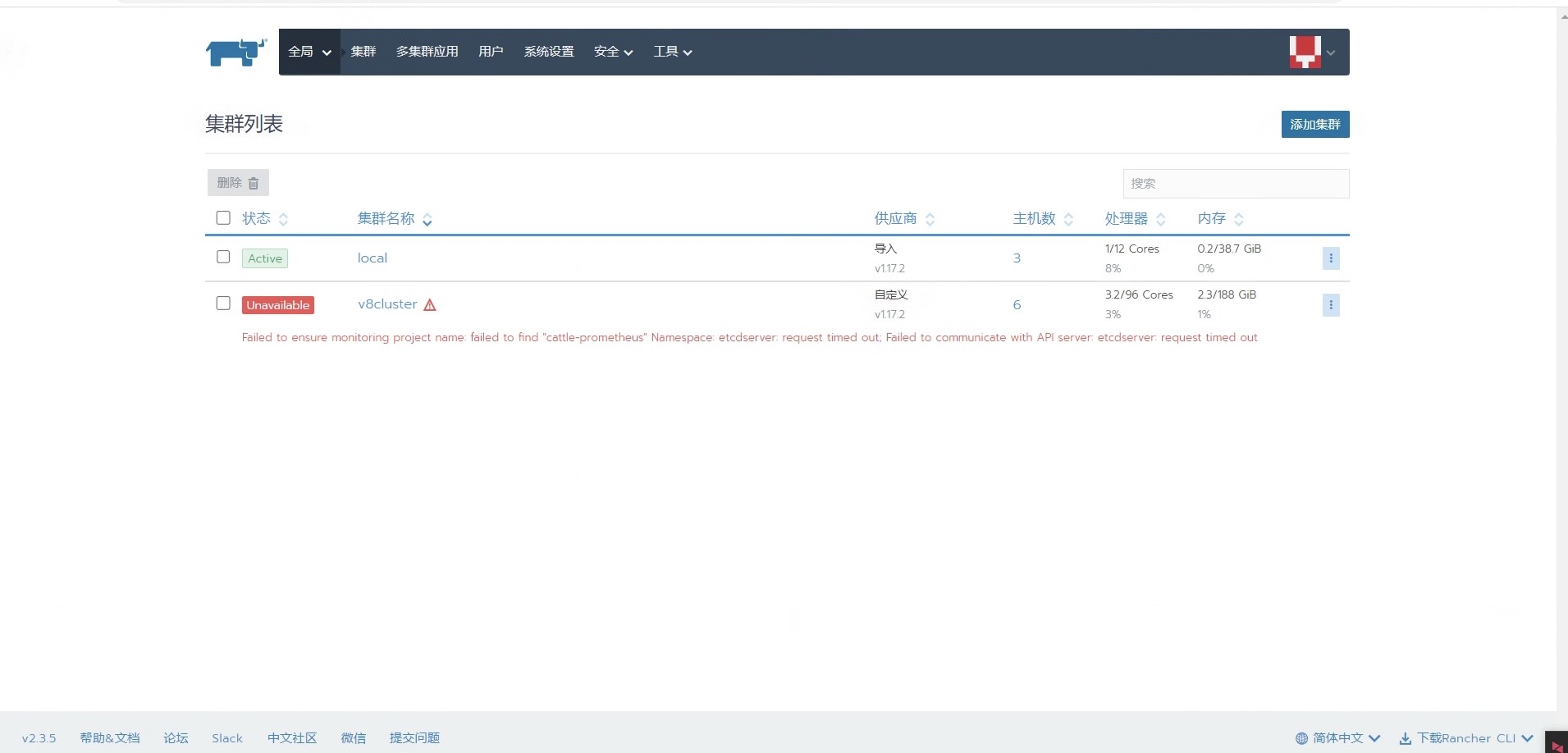
您好,能麻烦给帮忙看下这个报错吗Failed to ensure monitoring project name: failed to find “cattle-prometheus” Namespace: etcdserver: request timed out; Failed to communicate with API server: etcdserver: request timed out 重启过rancher也不能解决