闪光蜗牛
2023 年2 月 17 日 03:18
1
Rancher Server 设置
Rancher 版本:2.6.10
安装选项 (Docker install/Helm Chart): Docker install
如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:
在线或离线部署:离线
下游集群信息
Kubernetes 版本: 1.23
Cluster Type (Local/Downstream): Downstream
如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): 导入
用户信息
登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义):管理员
**主机操作系统:suse12sp5
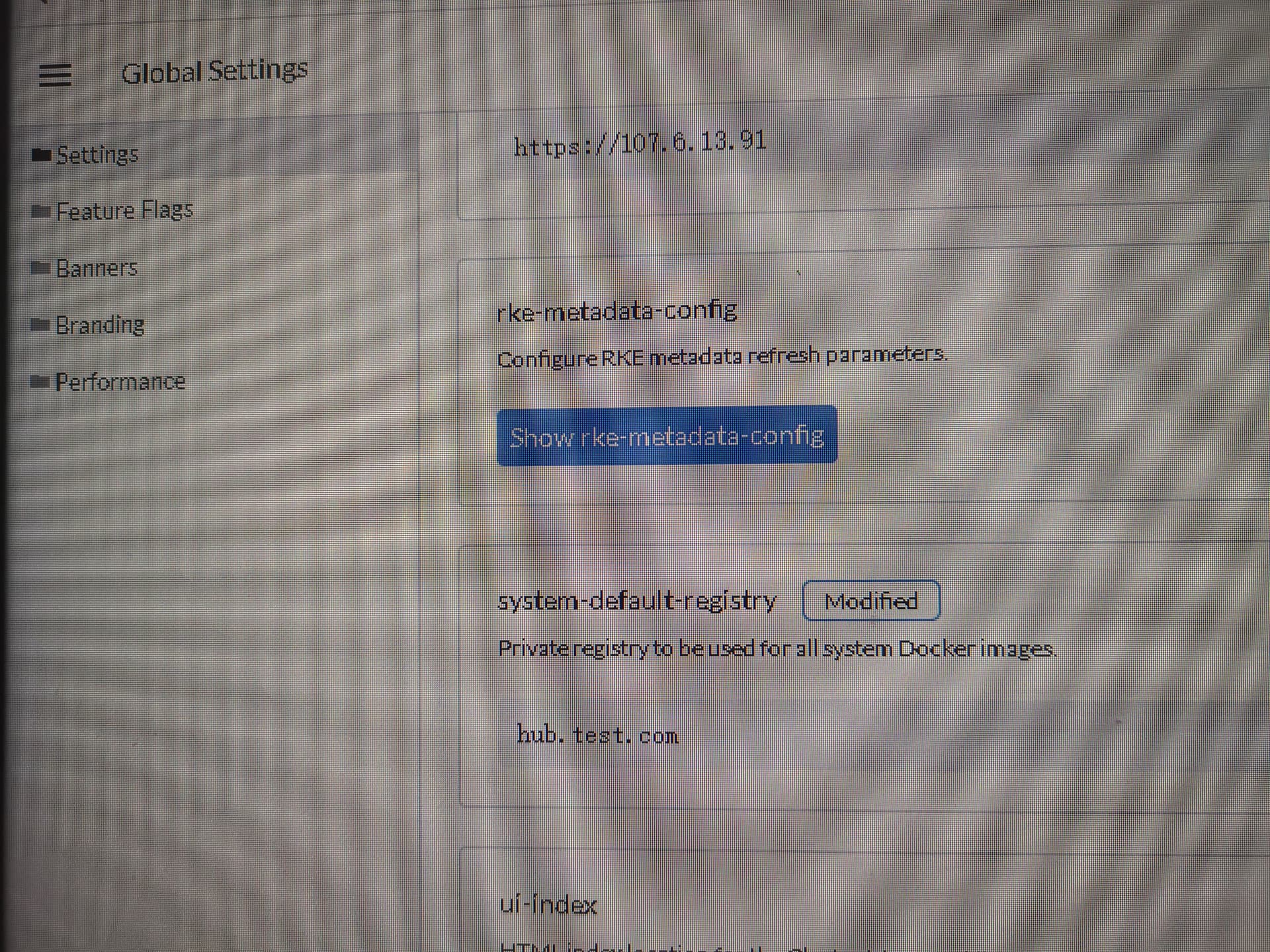
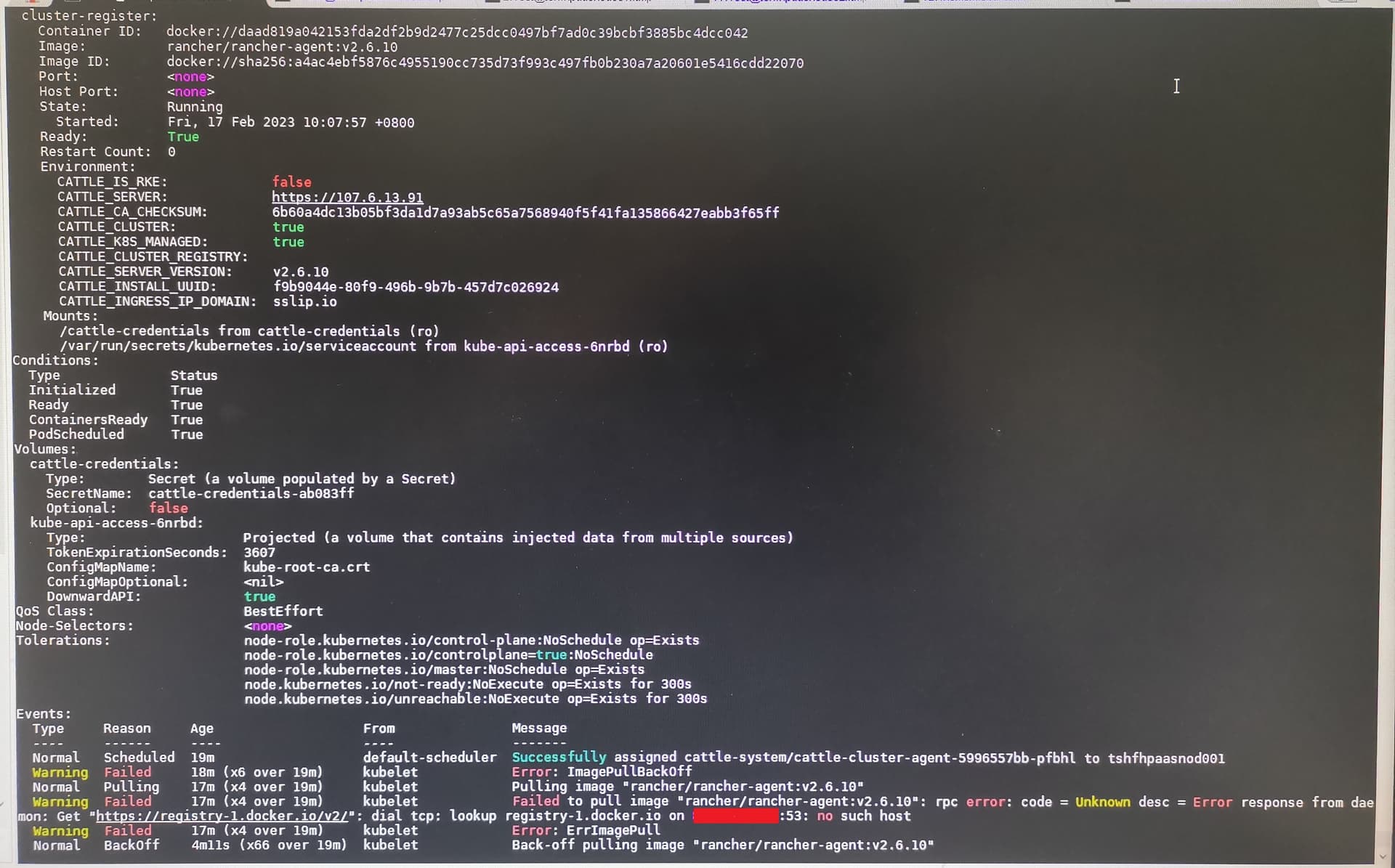
**问题描述:我使用离线方式部署单docker的rancher 2.6.10,目前进去面板后进行k8s 1.23集群导入工作,导入时候一直是pending,查看cattle-system下的pod情况,发现node尝试从rancher官方仓库拉取rancher-agent:v2.6.10,但我已经在全局配置中将系统默认仓库配置为我的仓库hub.test.com ,并且我在node上直接pull是可以成功,为什么这个配置没有在import时候生效呢?以前2.4、2.5版本这样做都是ok的
**重现步骤:配置全局仓库,进行导入
**结果:如问题描述
**预期结果:应能从hub.test.com拉取rancher-agent(我已经push上去),之后就能完成集群导入工作。目前我不得已在node上docker load镜像才能导入集群,显然这个做法在规模提高后不具备可行性。
**截图:
其他上下文信息:
日志
闪光蜗牛
2023 年2 月 17 日 09:29
4
我换了2.7.1还是有这个问题,看来都要修复这个bug了?
ksd
2023 年2 月 19 日 02:51
5
是的
闪光蜗牛
2023 年8 月 2 日 02:44
6
我下载了最新的2.6.13,这个问题还没有解决呀?我启动容器时候指定CATTLE_SYSTEM_DEFAULT_REGISTRY以后,import阶段还在尝试从外网下载rancher,该怎么办呢?
闪光蜗牛
2023 年8 月 2 日 03:10
8
我是用的指令是这样的:hub.test.com -e CATTLE_SYSTEM_CATALOG=bundled --privileged hub.test.com/rancher/rancher:v2.6.13
我期望启动后的rancher默认下载rancher-agent的仓库就是hub.test.com ,目前hub.test.com上面已经推送了rancher-server的v2.6.13版本和rancher-agent的v2.6.13版本。
但是当我进行import Existing的时候,我的集群引入一直处于pending状态,从kubectl查询指令来看,cattle-system空间内没有能够成功启动cluster-agent,rancher-agent的镜像没有拉取。hub.test.com/rancher/rancher-agent-2.6.9 , 我感觉这个是错误的主要原因。
我手工拉取镜像后tag为 rancher/rancher:v2.6.13就成功引入了集群,所以想求助下这个问题怎么解决呢?
ksd
2023 年8 月 2 日 07:43
9
针对 cluster-agent,有个参数可以指定:-e CATTLE_AGENT_IMAGE="registry.cn-hangzhou.aliyuncs.com/rancher/rancher-agent:v2.6.13"
闪光蜗牛
2023 年8 月 2 日 10:01
10
谢谢,这个方法奏效了。现在部署后,我发现好多节点在尝试启动helm-operation的pod,尝试拉取shell镜像,这个有什么作用?我可以取消这个特性吗?
闪光蜗牛
2023 年8 月 4 日 01:03
12
我从外网拿了2个镜像,一个shell,一个webhook,这样可以让这些pod正常启动。但是依然有问题,那个shell镜像(helm-operation)每过一段时间就会挂掉,然后再次启动,看日志一直是waiting for kubernetes api,然后若干分钟后状态变为timeout,之后就挂掉了,看不明白这些pod启动的机制,如果我不管它们,是否会对长期运行有负面影响?