Rancher Server 设置
- Rancher 版本:2.6.8
- 安装选项 (Docker install/Helm Chart): Helm Chart
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:k3s 1.22.4
- 在线或离线部署:在线
下游集群信息
- Kubernetes 版本: 1.23
- Cluster Type (Local/Downstream):
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): 自定义/导入
用户信息
- 登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义):
- 如果自定义,自定义权限集:admin
主机操作系统:
问题描述: rancher 2.6.8 pod间歇性重启,访问报错bad gateway或404,rancher pod日志报错如图所示,rt-vr66v我怀疑是自建的一个role,与role相关的操作只有删除了一个custom project member和custom project admin,不确定是不是相关?为什么不会连带删除呢?
重现步骤:
结果:
预期结果:
截图:
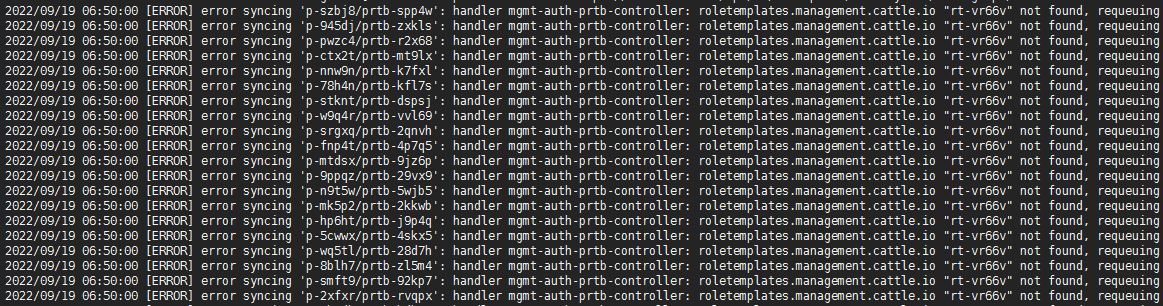

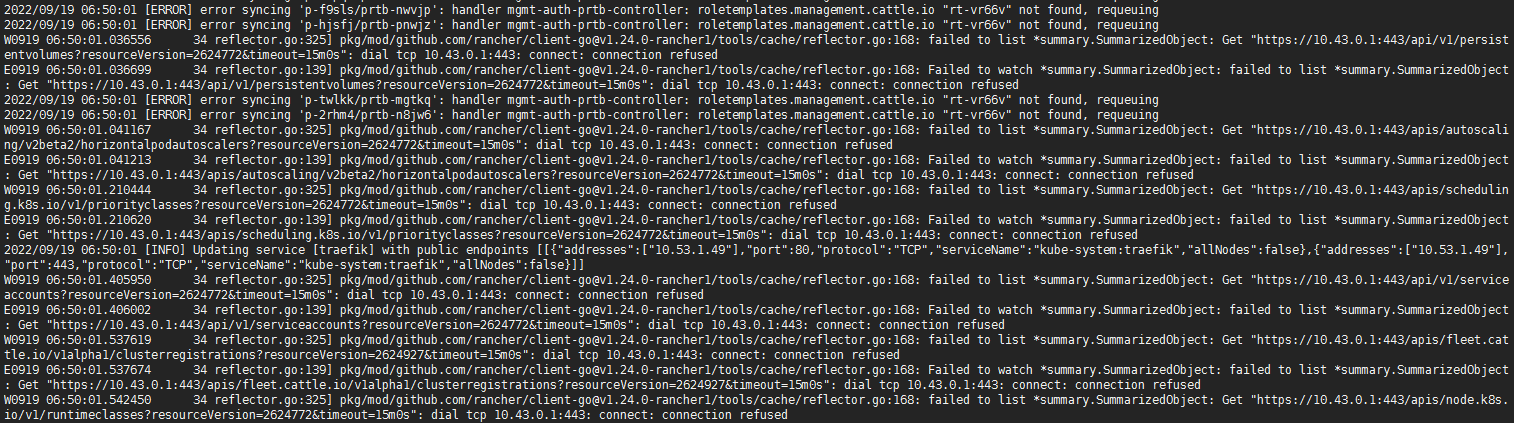
其他上下文信息:
日志