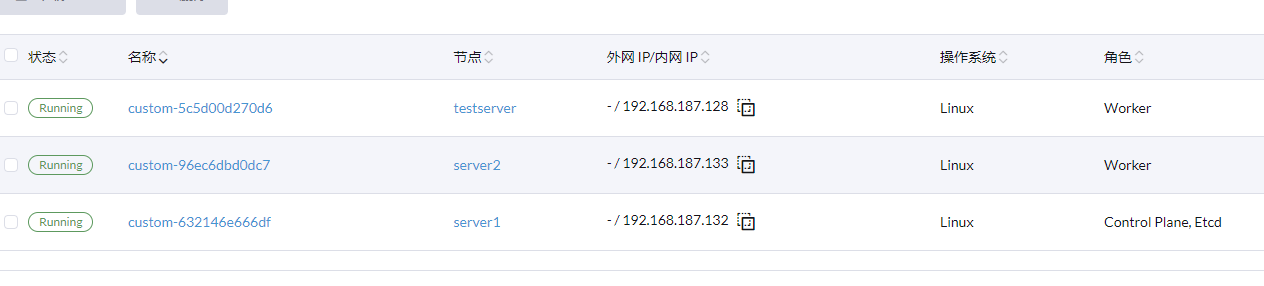
环境信息:
RKE2 版本:
rke2 version v1.28.10+rke2r1 (b0d0d687d98f4fa015e7b30aaf2807b50edcc5d7)
go version go1.21.9 X:boringcrypto
节点 CPU 架构,操作系统和版本:
Linux test22 5.15.0-118-generic #128-Ubuntu SMP Fri Jul 5 09:28:59 UTC 2024 x86_64 x86_64 x86_64 GNU/Linux Ubuntu 22.04.4
集群配置:
“1 servers, 1 agents”
问题描述:
使用docker容器启动的rancher来创建rke2的集群,选择两个虚拟机作为测试机器,其中一个作为server担任etcd和control角色,另外一个agent机器担任worker角色,创建自定义集群后,用命令分别注册两个节点机器,server的机器正常工作显示wait for agent connect,agent机器并无反应 Waiting for Node Ref状态
重现步骤:
1、docker安装rancher
2、创建自定义集群
3、虚拟机分别运行Ubuntu server 22.04两个虚拟机
4、注册server角色为etcd和control
curl --insecure -fL https://192.168.1.7/system-agent-install.sh | sudo sh -s - --server https://192.168.1.7 --label ‘cattle.io/os=linux’ --token 2f5jpv9wrvd6qw4n6l8nb9g2wmplc7fshzh6jdpxshg74p68j96nvl --ca-checksum 65115a0a4dd5b8067a0b8dcd2dcc3abac1a7fdd381ea63a48e86524708d3ec61 --etcd --controlplane
5、注册agent角色为worker
curl --insecure -fL https://192.168.1.7/system-agent-install.sh | sudo sh -s - --server https://192.168.1.7 --label ‘cattle.io/os=linux’ --token 2f5jpv9wrvd6qw4n6l8nb9g2wmplc7fshzh6jdpxshg74p68j96nvl --ca-checksum 65115a0a4dd5b8067a0b8dcd2dcc3abac1a7fdd381ea63a48e86524708d3ec61 --worker
预期结果:
rke服务节点和agent节点都能正常启动
实际结果:
server的机器正常工作显示wait for agent connect,agent机器并无反应 Waiting for Node Ref状态

日志
rke2-server log (ETCD、CONTROL)
Aug 22 03:08:11 server1 rke2[2278]: time=“2024-08-22T03:08:11Z” level=info msg=“Reconciling snapshot ConfigMap data”
Aug 22 03:08:12 server1 rke2[2278]: time=“2024-08-22T03:08:12Z” level=error msg=“error syncing ‘kube-system/rke2-coredns’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-coredns" not found, requeuing”
Aug 22 03:08:13 server1 rke2[2278]: time=“2024-08-22T03:08:13Z” level=error msg=“error syncing ‘kube-system/rke2-ingress-nginx’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-ingress-nginx" not found, requeuing”
Aug 22 03:08:14 server1 rke2[2278]: time=“2024-08-22T03:08:14Z” level=info msg=“Running kube-proxy --cluster-cidr=10.42.0.0/16 --conntrack-max-per-core=0 --conntrack-tcp-timeout-close-wait=0s --conntrack-tcp-timeout-established=0s --healthz-bind-address=127.0.0.1 --hostname-override=server1 --kubeconfig=/var/lib/rancher/rke2/agent/kubeproxy.kubeconfig --proxy-mode=iptables”
Aug 22 03:08:14 server1 rke2[2278]: time=“2024-08-22T03:08:14Z” level=error msg=“error syncing ‘kube-system/rke2-metrics-server’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-metrics-server" not found, requeuing”
Aug 22 03:08:16 server1 rke2[2278]: time=“2024-08-22T03:08:16Z” level=error msg=“error syncing ‘kube-system/rke2-snapshot-controller-crd’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-snapshot-controller-crd" not found, requeuing”
Aug 22 03:08:16 server1 rke2[2278]: time=“2024-08-22T03:08:16Z” level=error msg=“error syncing ‘kube-system/rke2-snapshot-controller’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-snapshot-controller" not found, requeuing”
Aug 22 03:08:16 server1 rke2[2278]: time=“2024-08-22T03:08:16Z” level=error msg=“error syncing ‘kube-system/rke2-snapshot-validation-webhook’: handler helm-controller-chart-registration: helmcharts.helm.cattle.io "rke2-snapshot-validation-webhook" not found, requeuing”
Aug 22 03:08:17 server1 rke2[2278]: time=“2024-08-22T03:08:17Z” level=info msg=“Adding node server1-4a976f35 etcd status condition”
Aug 22 03:14:34 server1 rke2[2278]: time=“2024-08-22T03:14:34Z” level=info msg=“Tunnel authorizer set Kubelet Port 10250”
rancher-system-agent log (WORKER)
Aug 22 02:52:32 server2 rancher-system-agent[2040]: time=“2024-08-22T02:52:32Z” level=info msg=“Starting /v1, Kind=Secret controller”
Aug 22 03:29:46 server2 systemd[1]: Stopping Rancher System Agent…
Aug 22 03:29:47 server2 systemd[1]: rancher-system-agent.service: Deactivated successfully.
Aug 22 03:29:47 server2 systemd[1]: Stopped Rancher System Agent.
Aug 22 03:29:47 server2 systemd[1]: rancher-system-agent.service: Consumed 1.188s CPU time.
– Boot f7813d197d614358b4dd9f41d2bb22ab –
Aug 22 03:30:24 server2 systemd[1]: Started Rancher System Agent.
Aug 22 03:30:25 server2 rancher-system-agent[870]: time=“2024-08-22T03:30:25Z” level=info msg=“Rancher System Agent version v0.3.6 (41c07d0) is starting”
Aug 22 03:30:25 server2 rancher-system-agent[870]: time=“2024-08-22T03:30:25Z” level=info msg=“Using directory /var/lib/rancher/agent/work for work”
Aug 22 03:30:25 server2 rancher-system-agent[870]: time=“2024-08-22T03:30:25Z” level=info msg=“Starting remote watch of plans”
Aug 22 03:30:26 server2 rancher-system-agent[870]: time=“2024-08-22T03:30:26Z” level=info msg=“Starting /v1, Kind=Secret controller”