Rancher Server 设置
- Rancher 版本:2.6.6
- 安装选项 (Docker install/Helm Chart): Helm
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:k3s
- 在线或离线部署:在线
下游集群信息
- Kubernetes 版本: v1.23.14
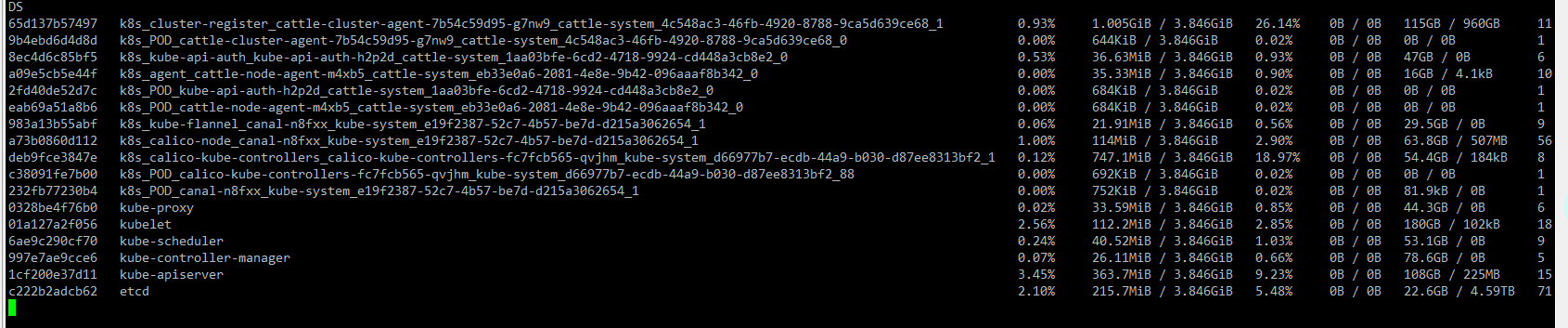
**问题描述:三个etcd节点的配置都是2C4G,现在三个etcd节点中,节点二内存占用过高,可用内存500M上下,在后台ui中看是85%,使用docker ststs 发现k8s_cluster-register_cattle-cluster-agent占用比较大,可以进行容器重启吗?重启对集群的影响是什么
**截图:
其他上下文信息:
日志