环境信息:
rancher的版本为:v2.7.9
3.10.0-1160.99.1.el7.x86_64 #1 SMP Thu Aug 10 10:46:21 EDT 2023 x86_64 x86_64 x86_64 GNU/Linux
这是测试节点,只有一个server节点问题描述:
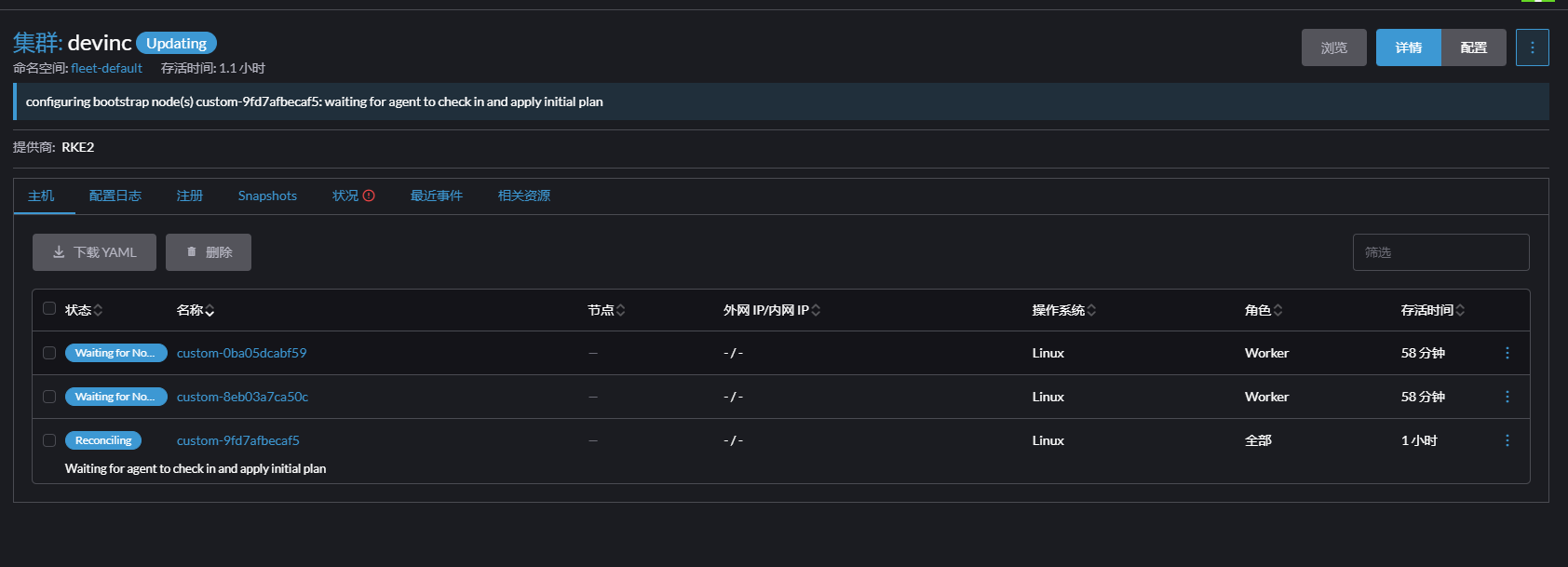
在rancher中创建k8s的时候,集群报错:Waiting for agent to check in and apply initial plan,另外我不清楚是不是跟rancher v2.7.9版本有关系重现步骤:
日志
rke2-server.service holdoff time over, scheduling restart.
/usr/bin/systemctl is-enabled --quiet nm-cloud-setup.service
ksd
2023 年11 月 20 日 06:57
2
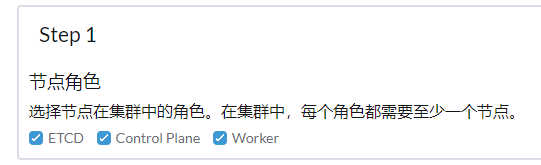
看描述,你的集群里应该只添加了一个节点,添加节点时,选择的节点的角色都是什么?
ksd
2023 年11 月 21 日 03:00
4
这里有一些 rke2 的基础命令和日志的排查,你可以根据链接去排查下:RKE2 commands
麻烦能帮我看下这个报错吗
查看containerd日志,是正常的namespace=k8s.io namespace=k8s.io namespace=k8s.io
我现在主机master节点后,这个报错Configuring bootstrap node(s) custom-e136bf3d2c94: waiting for probes: calico
[root@localhost ~]# journalctl -f -u rancher-system-agenthelm.cattle.io/v1 ” type=“Normal” reason=“ApplyJob” message=“Applying HelmChart using Job kube-system/helm-install-rke2-ingress-nginx”helm.cattle.io/v1 ” type=“Normal” reason=“ApplyJob” message=“Applying HelmChart using Job kube-system/helm-install-rke2-ingress-nginx”helmcharts.helm.cattle.io "rke2-metrics-server" not found, requeuing”helm.cattle.io/v1 ” type=“Normal” reason=“ApplyJob” message=“Applying HelmChart using Job kube-system/helm-install-rke2-metrics-server”helm.cattle.io/v1 ” type=“Normal” reason=“ApplyJob” message=“Applying HelmChart using Job kube-system/helm-install-rke2-metrics-server”
yatou
2024 年1 月 22 日 07:07
7
解决了吗,我这边绑定一个域名之后,重新创建集群就这个,完犊子了
yatou
2024 年1 月 22 日 07:54
9
集群报错:Waiting for agent to check in and apply initial plan