Rancher Server 设置
- Rancher 版本:v2.6.13
- 安装选项 (Docker install/Helm Chart): helm Chart
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:k3s
- 在线或离线部署:离线部署
下游集群信息
- Kubernetes 版本: v1.21.7+k3s1
- Cluster Type (Local/Downstream): Downstream
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): 导入集群
用户信息
- 登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义):
主机操作系统:ubuntu 20.04
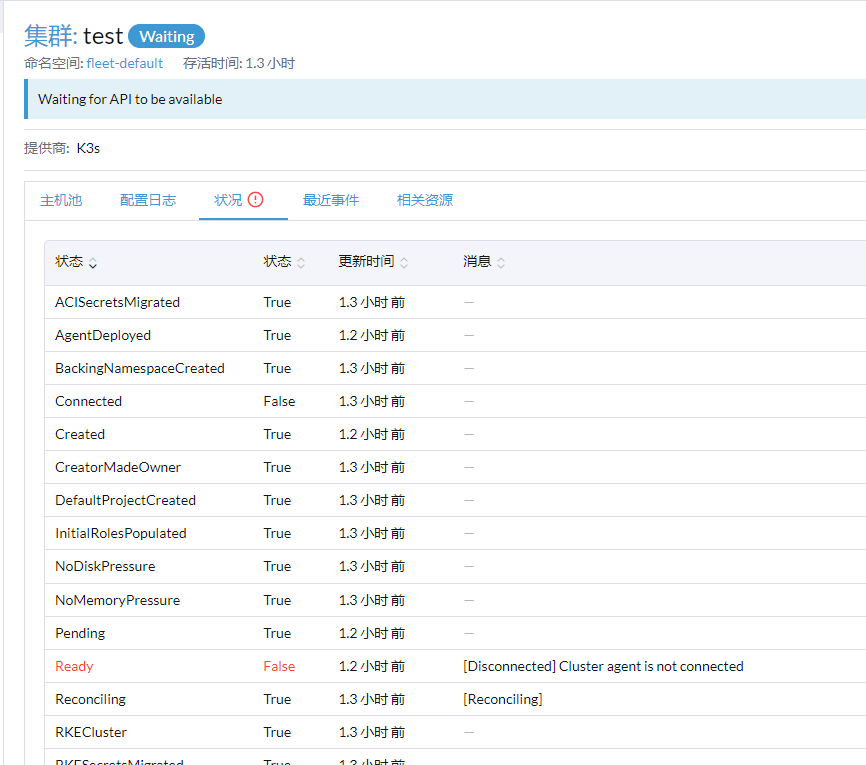
问题描述:导入现有的k3s集群一直处于waitting阶段,
**重现步骤:1、导入k3s集群:curl --insecure -sfL https://rancher-server.com/v3/import/rl4hg2kg8shgqx76knrwvnh4gnnwrx5fhtf45j6x4p66nzbjv7zf8j_c-m-lcl26bqj.yaml > rancher-agent.yaml
2、修改rancher-agent.yaml,添加hostAlisas,修改images至私有仓库.
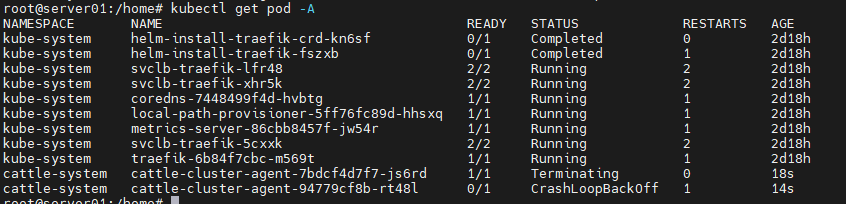
3、然后通过kubectl apply -f rancher-agent.yaml 出现两个cattle-cluster-agent pod,过一会会只剩下一个pod并且显示域名解析失败
4、重新执行kubectl apply -f rancher-agent.yaml,pod正常运行但停留在这个阶段
5、集群还是waitting
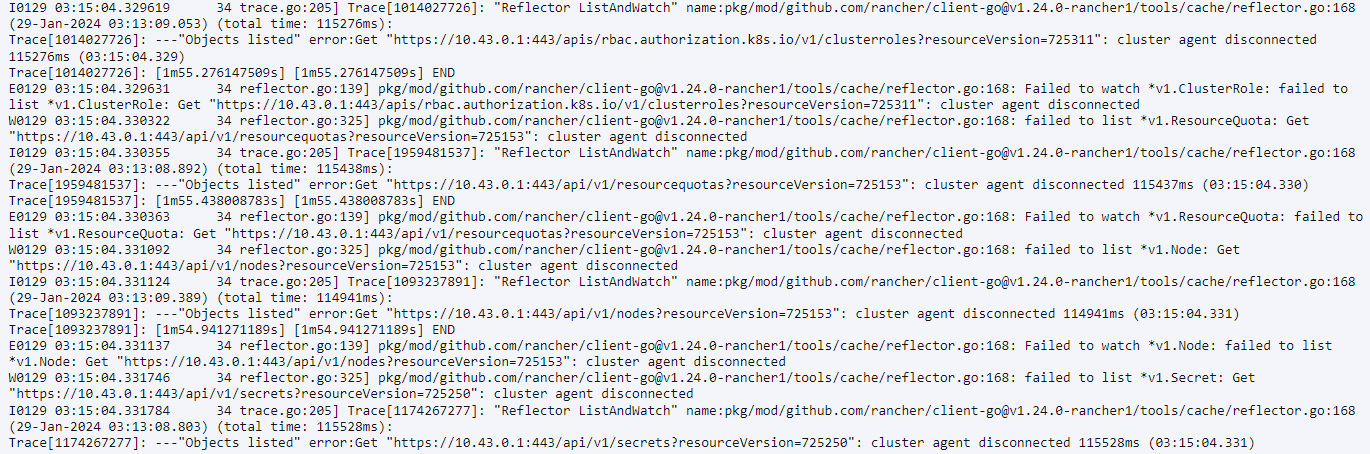
6、rancher-server 的logs如下,只能上传五张图片,我挑选了可能有用的信息:
**
结果:
预期结果:
截图:
其他上下文信息:
[/details]
ksd
3
好像不是这个问题,我通过kubectl edit clusters.management.cattle.io 这个命令。
在local跟导入集群都没有GlobalAdminsSynced 这个type。导入集群中condition如下:
- lastUpdateTime: “2024-01-29T06:17:41Z”
message: Waiting for API to be available
status: Unknown
type: Waiting
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: NoDiskPressure
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: NoMemoryPressure
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: SecretsMigrated
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: ServiceAccountSecretsMigrated
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: RKESecretsMigrated
- lastUpdateTime: “2024-01-29T06:17:41Z”
status: “True”
type: ACISecretsMigrated
- lastUpdateTime: “2024-01-29T06:17:48Z”
status: “False”
type: Connected
- lastUpdateTime: “2024-01-29T06:23:32Z”
status: “True”
type: SystemAccountCreated
- lastUpdateTime: “2024-01-29T06:23:33Z”
status: “True”
type: AgentDeployed
- lastUpdateTime: “2024-01-29T06:23:33Z”
message: Cluster agent is not connected
reason: Disconnected
status: “False”
type: Ready
- lastUpdateTime: “2024-01-29T06:23:33Z”
status: “True”
type: Updated
请问以下,这个info:Requesting kubelet certificate regeneration 是在干什么。cattle-cluster-agent的log到这里就停了,看起来是准备验证吗
ksd
6
这个日志没问题。
你这样,你试试将导入的 cluster agent 的 deployment 删掉,然后不修改镜像仓库的前缀,使用默认的 yaml 重新导入试试。
我怀疑你第一个图中的agent 报错,是因为没拉到镜像。
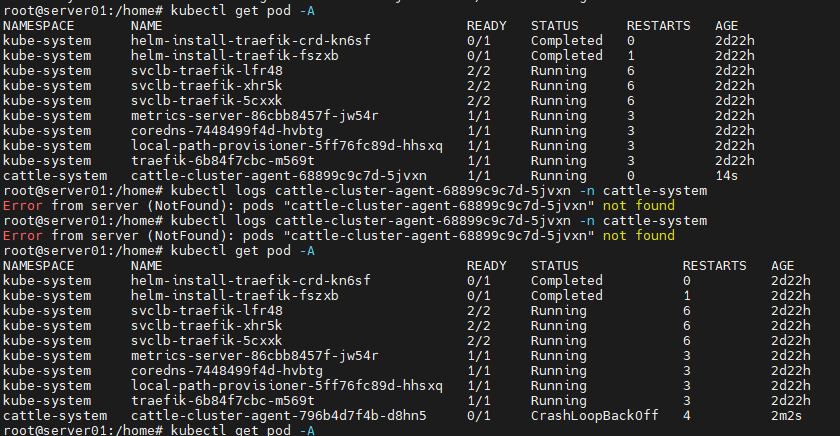
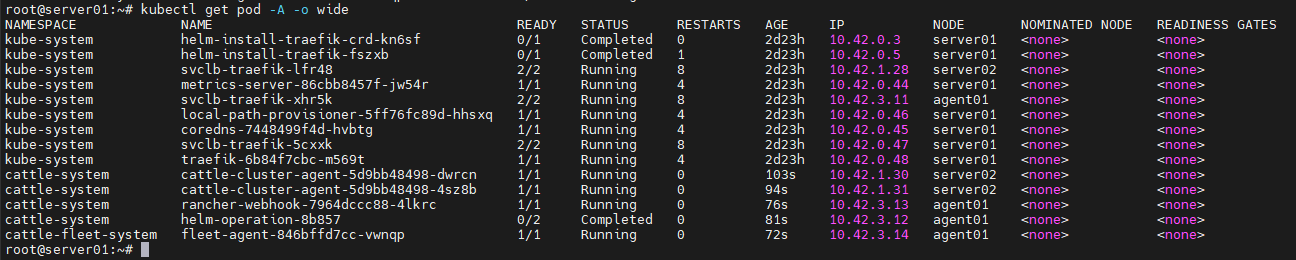
我删了deployment,修改image执行kubectl apply -f rancher-agent.yaml重新导入,出现情况:
1、一个pod运行一段时候后,消失了,换成了一个新的pod。
2、新的pod的hostAlisas没了,如下:
3、我将这个pod导出kubectl get pod -o json > xx,发现image没修改成功,而且没有hostAlisas
4、我再执行一次apply -f 就成功了
我的操作顺序:1、kubectl delete deployment cattle-cluster-agent -n cattle-system
2、修改rancher-agent.yaml中的image,保存
3、kubectl apply -f rancher-agent.yaml
4、发现上面的问题后 我又执行一次操作 3
我是不是操作有问题
jacie
9
在导入集群的时候,执行了删除cluster-agent操作后,rancher会自动下发新的cluster-agent,你可以试下不删除,直接在下游集群修改rancher-agent yaml
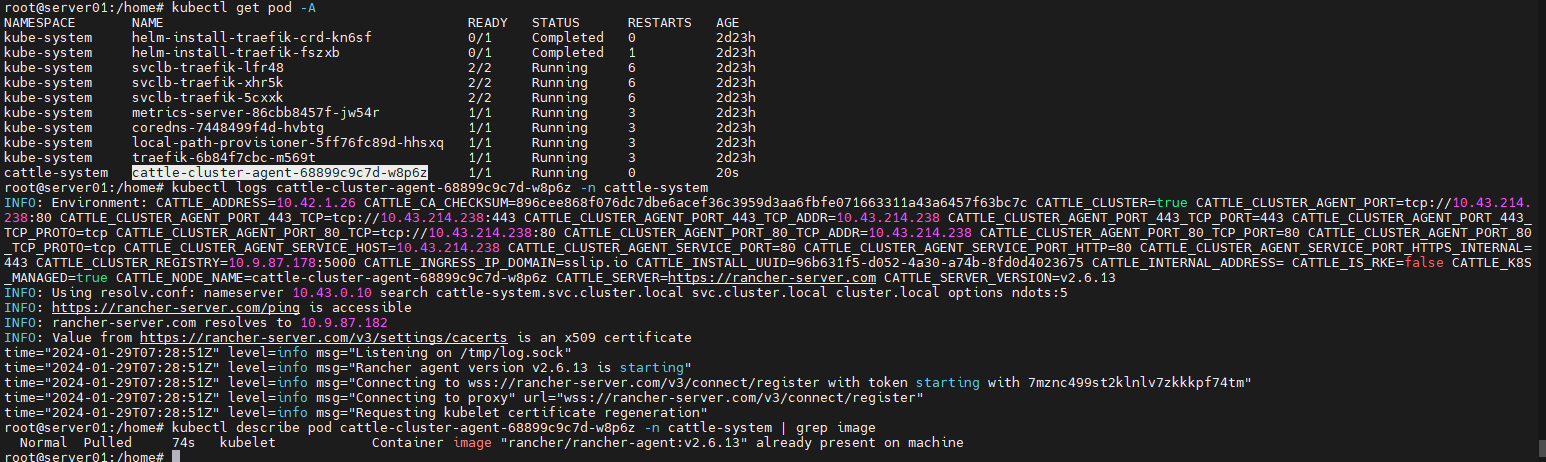
直接修改rancher-agent.yaml 然后kubectl apply -f 吗?
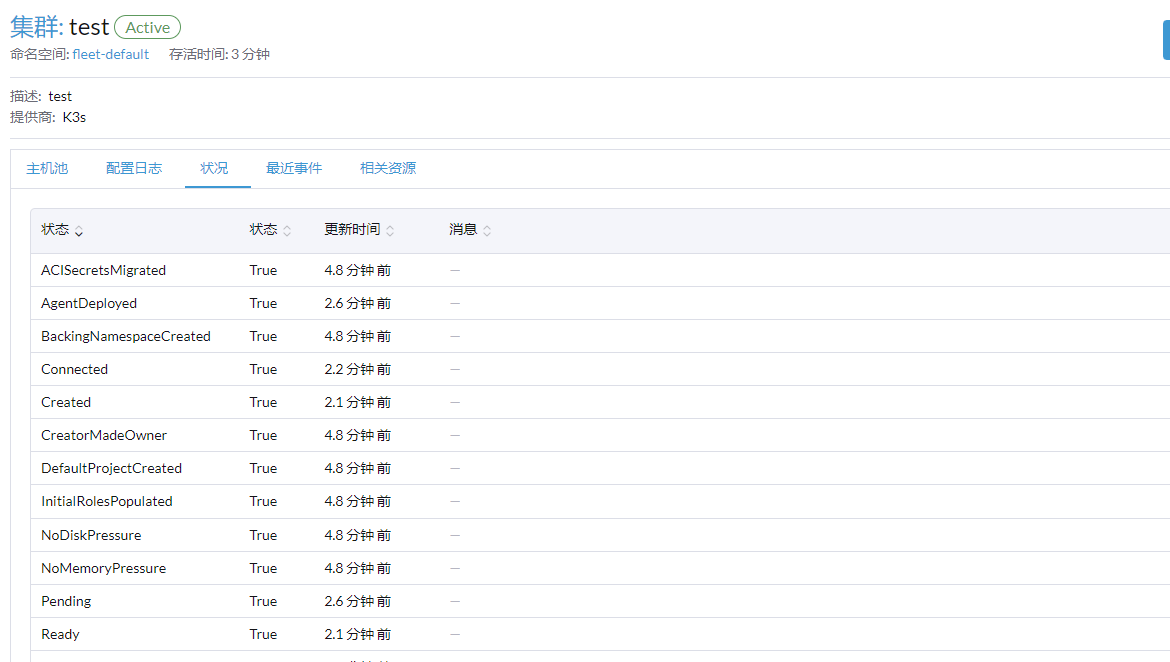
我这个操作下来image改成功了,然后pod也运行正常,虽然重复执行了一次kubectl apply -f 最终效果应该是满足了吧。
因为我好像记得,我第一次导入的时候也是这样,会产生两个pod:两个pod一个有我添加的hostAlisas,一个没有hostAlisas。最后有hostAlisas的pod就自动消失了,剩下那个有问题,我再执行一次apply,就能正常运行一个rancher-agent的pod。
jacie
11
就是你导入的时候直接执行curl命令,然后kubectl edit修改一下cattle-agent deployment的yaml试一下
成功了  ,这是啥原因,只能edit吗
,这是啥原因,只能edit吗
还有一个问题,这个是默认启动两个cluster-agent pod吗
谢谢大佬,我还有一个小问题,能不能设置导入集群的那个yaml中的image,特别是在rancher UI中删除集群cleanup的那个image。我删除一些只能私有仓库集群的时候,cleanup的pod无法获取镜像。
jacie
14
如果环境无法连接公网,建议设置全局级别的私有镜像仓库。
这个全局设置是指在rancher UI上面设置吗?