Rancher Server 设置
- Rancher 版本:v2.6.13
- 安装选项 (Docker install/Helm Chart): Helm Chart
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:RKE1
- 在线或离线部署:在线
下游集群信息
- Kubernetes 版本: v1.24.17
- Cluster Type (Local/Downstream): Downstream
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): 自定义
用户信息
- 登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义):管理员
- 如果自定义,自定义权限集:
主机操作系统:
CentOS7.9
问题描述:
问题1:Rancher最近不定时出现重启,UI报502,很频繁,有启动失败的情况,并且启动过程很慢。
排查发现Local(RKE)集群运行均正常,操作系统里也没有oom等相关错误发现,有什么排查思路吗,rancher在什么情况下才会触发重启?
问题2:
calico-kube-controllers 也在频繁重启,kubelet一直在报probe faild,但集群使用一切正常,日志如下。
重现步骤:
结果:
预期结果:
截图:
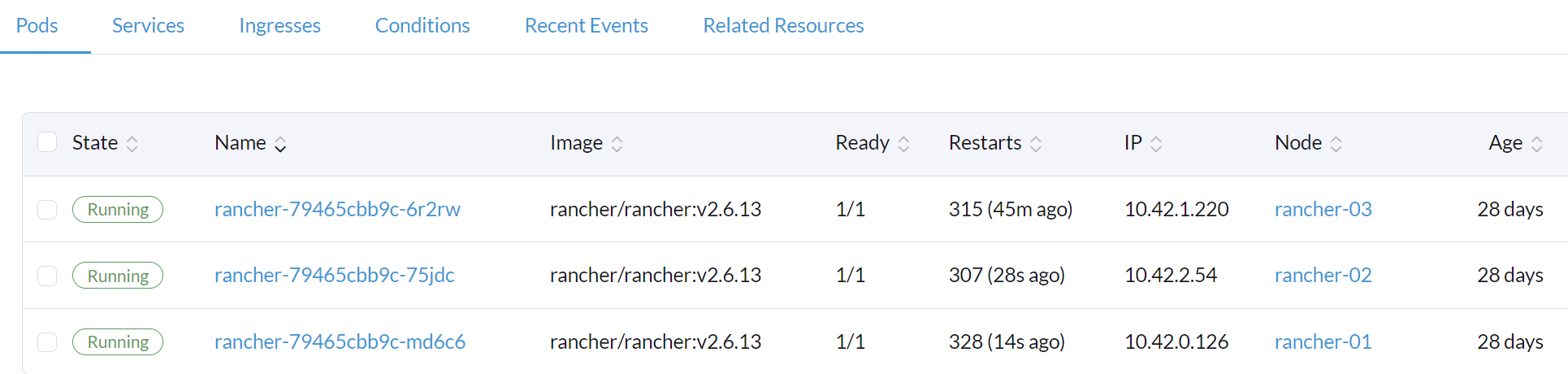
其他上下文信息:
日志
# 重启启动失败的容器中的日志
2024/01/31 01:44:07 [INFO] Rancher version v2.6.13 (e91bb0533) is starting
2024/01/31 01:44:07 [INFO] Rancher arguments {ACMEDomains:[] AddLocal:true Embedded:false BindHost: HTTPListenPort:80 HTTPSListenPort:443 K8sMode:auto Debug:false Trace:false NoCACerts:true AuditLogPath:/var/log/auditlog/rancher-api-audit.log AuditLogMaxage:10 AuditLogMaxsize:100 AuditLogMaxbackup:10 AuditLevel:0 Features: ClusterRegistry:}
2024/01/31 01:44:07 [INFO] Listening on /tmp/log.sock
E0131 01:47:25.718555 33 request.go:977] Unexpected error when reading response body: read tcp 10.42.0.126:46592->10.43.0.1:443: read: connection reset by peer
2024/01/31 01:49:24 [FATAL] 1 error occurred:
* unexpected error when reading response body. Please retry. Original error: read tcp 10.42.0.126:46592->10.43.0.1:443: read: connection reset by peer
# 重启成功的容器中的日志,启动每次会在Listening on /tmp/log.sock卡4-5分钟。
2024/01/31 01:50:18 [INFO] Rancher version v2.6.13 (e91bb0533) is starting
2024/01/31 01:50:18 [INFO] Rancher arguments {ACMEDomains:[] AddLocal:true Embedded:false BindHost: HTTPListenPort:80 HTTPSListenPort:443 K8sMode:auto Debug:false Trace:false NoCACerts:true AuditLogPath:/var/log/auditlog/rancher-api-audit.log AuditLogMaxage:10 AuditLogMaxsize:100 AuditLogMaxbackup:10 AuditLevel:0 Features: ClusterRegistry:}
2024/01/31 01:50:18 [INFO] Listening on /tmp/log.sock
2024/01/31 01:54:21 [INFO] Running in clustered mode with ID 10.42.0.126, monitoring endpoint cattle-system/rancher
2024/01/31 01:54:32 [INFO] Applying CRD features.management.cattle.io
2024/01/31 01:55:49 [INFO] Applying CRD navlinks.ui.cattle.io
2024/01/31 01:55:52 [INFO] Applying CRD clusters.management.cattle.io
2024/01/31 01:55:54 [INFO] Applying CRD apiservices.management.cattle.io
# calico-kube-controllers相关日志(包含kubelet和calico-kube-controllers日志)
## kubelet日志
I0123 02:43:05.979993 27324 prober.go:121] "Probe failed" probeType="Readiness" pod="kube-system/calico-kube-controllers-7b9bc56d68-5t6jt" podUID=f5bd5d97-ab09-466b-a9da-7980fde19599 containerName="calico-kube-controllers" probeResult=failure output=<
Failed to read status file /status/status.json: unexpected end of JSON input
>
I0123 02:43:16.114907 27324 prober.go:121] "Probe failed" probeType="Readiness" pod="kube-system/calico-kube-controllers-7b9bc56d68-5t6jt" podUID=f5bd5d97-ab09-466b-a9da-7980fde19599 containerName="calico-kube-controllers" probeResult=failure output=<
initialized to false
>
I0123 02:43:16.126814 27324 prober.go:121] "Probe failed" probeType="Liveness" pod="kube-system/calico-kube-controllers-7b9bc56d68-5t6jt" podUID=f5bd5d97-ab09-466b-a9da-7980fde19599 containerName="calico-kube-controllers" probeResult=failure output=<
initialized to false
>
I0123 02:43:26.122109 27324 prober.go:121] "Probe failed" probeType="Liveness" pod="kube-system/calico-kube-controllers-7b9bc56d68-5t6jt" podUID=f5bd5d97-ab09-466b-a9da-7980fde19599 containerName="calico-kube-controllers" probeResult=failure output=<
Error reaching apiserver: <nil> with http status code: 500
>
I0123 02:43:26.131142 27324 prober.go:121] "Probe failed" probeType="Readiness" pod="kube-system/calico-kube-controllers-7b9bc56d68-5t6jt" podUID=f5bd5d97-ab09-466b-a9da-7980fde19599 containerName="calico-kube-controllers" probeResult=failure output=<
Error reaching apiserver: <nil> with http status code: 500
## calico-kube-controllers日志
2024-01-31 03:50:24.125 [INFO][1] main.go 99: Loaded configuration from environment config=&config.Config{LogLevel:"info", WorkloadEndpointWorkers:1, ProfileWorkers:1, PolicyWorkers:1, NodeWorkers:1, Kubeconfig:"", DatastoreType:"kubernetes"}
W0131 03:50:24.133012 1 client_config.go:615] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work.
2024-01-31 03:50:24.136 [INFO][1] main.go 120: Ensuring Calico datastore is initialized
2024-01-31 03:50:27.031 [INFO][1] main.go 161: Getting initial config snapshot from datastore
2024-01-31T03:50:31.160936447Z 2024-01-31 03:50:31.160 [INFO][1] main.go 164: Got initial config snapshot
2024-01-31T03:50:31.161932124Z 2024-01-31 03:50:31.161 [INFO][1] watchersyncer.go 89: Start called
2024-01-31T03:50:31.161986541Z 2024-01-31 03:50:31.161 [INFO][1] main.go 181: Starting status report routine
2024-01-31T03:50:31.162061246Z 2024-01-31 03:50:31.161 [INFO][1] main.go 190: Starting Prometheus metrics server on port 9094
2024-01-31T03:50:31.162441035Z 2024-01-31 03:50:31.162 [INFO][1] main.go 467: Starting informer informer=&cache.sharedIndexInformer{indexer:(*cache.cache)(0xc00059e258), controller:cache.Controller(nil), processor:(*cache.sharedProcessor)(0xc0006320e0), cacheMutationDetector:cache.dummyMutationDetector{}, listerWatcher:(*cache.ListWatch)(0xc00059e240), objectType:(*v1.Pod)(0xc000aa6800), resyncCheckPeriod:0, defaultEventHandlerResyncPeriod:0, clock:(*clock.RealClock)(0x2e335b0), started:false, stopped:false, startedLock:sync.Mutex{state:0, sema:0x0}, blockDeltas:sync.Mutex{state:0, sema:0x0}, watchErrorHandler:(cache.WatchErrorHandler)(nil)}
2024-01-31T03:50:31.162482684Z 2024-01-31 03:50:31.162 [INFO][1] main.go 467: Starting informer informer=&cache.sharedIndexInformer{indexer:(*cache.cache)(0xc00059e2a0), controller:cache.Controller(nil), processor:(*cache.sharedProcessor)(0xc000632150), cacheMutationDetector:cache.dummyMutationDetector{}, listerWatcher:(*cache.ListWatch)(0xc00059e288), objectType:(*v1.Node)(0xc000240300), resyncCheckPeriod:0, defaultEventHandlerResyncPeriod:0, clock:(*clock.RealClock)(0x2e335b0), started:false, stopped:false, startedLock:sync.Mutex{state:0, sema:0x0}, blockDeltas:sync.Mutex{state:0, sema:0x0}, watchErrorHandler:(cache.WatchErrorHandler)(nil)}
2024-01-31T03:50:31.162569784Z 2024-01-31 03:50:31.162 [INFO][1] main.go 473: Starting controller ControllerType="Node"
2024-01-31T03:50:31.163004811Z 2024-01-31 03:50:31.162 [INFO][
1] controller.go 189: Starting Node controller
2024-01-31T03:50:31.163277596Z 2024-01-31 03:50:31.162 [INFO][1] watchersyncer.go 127: Sending status update Status=wait-for-ready
2024-01-31T03:50:31.163345895Z 2024-01-31 03:50:31.163 [INFO][1] syncer.go 78: Node controller syncer status updated: wait-for-ready
2024-01-31T03:50:31.163382352Z 2024-01-31 03:50:31.163 [INFO][1] watchersyncer.go 147: Starting main event processing loop
2024-01-31T03:50:31.163640803Z 2024-01-31 03:50:31.163 [INFO][1] watchercache.go 175: Full resync is required ListRoot="/calico/ipam/v2/assignment/"
2024-01-31T03:50:31.169220139Z 2024-01-31 03:50:31.168 [INFO][1] watchercache.go 175: Full resync is required ListRoot="/calico/resources/v3/projectcalico.org/nodes"
2024-01-31T03:50:31.170779313Z 2024-01-31 03:50:31.170 [INFO][1] resources.go 350: Main client watcher loop
2024-01-31T03:50:31.172960296Z 2024-01-31 03:50:31.172 [INFO][1] watchercache.go 273: Sending synced update ListRoot="/calico/ipam/v2/assignment/"
2024-01-31T03:50:31.173254708Z 2024-01-31 03:50:31.172 [INFO][1] watchersyncer.go 209: Received InSync event from one of the watcher caches
2024-01-31T03:50:31.173310980Z 2024-01-31 03:50:31.173 [INFO][1] watchersyncer.go 127: Sending status update Status=resync
2024-01-31 03:50:31.173 [INFO][1] syncer.go 78: Node controller syncer status updated: resync
2024-01-31 03:50:31.208 [INFO][1] watchercache.go 273: Sending synced update ListRoot="/calico/resources/v3/projectcalico.org/nodes"
2024-01-31 03:50:31.209 [INFO][1] watchersyncer.go 209: Received InSync event from one of the watcher caches
2024-01-31 03:50:31.209 [INFO][1] watchersyncer.go 221: All watchers have sync'd data - sending data and final sync
2024-01-31 03:50:31.209 [INFO][1] watchersyncer.go 127: Sending status update Status=in-sync
2024-01-31T03:50:31.210556797Z 2024-01-31 03:50:31.209 [INFO][1] syncer.go 78: Node controller syncer status updated: in-sync
2024-01-31 03:50:31.364 [INFO][1] ipam.go 201: Will run periodic IPAM sync every 7m30s
2024-01-31T03:50:31.365052446Z 2024-01-31 03:50:31.364 [INFO][1] ipam.go 279: Syncer is InSync, kicking sync channel status=in-sync
2024-01-31 03:50:31.867 [INFO][1] hostendpoints.go 177: successfully synced all hostendpoints
2024-01-31T03:50:45.933670541Z 2024-01-31 03:50:45.933 [ERROR][1] main.go 278: Received bad status code from apiserver error=an error on the server ("[+]ping ok\n[+]log ok\n[-]etcd failed: reason withheld\n[+]poststarthook/start-kube-apiserver-admission-initializer ok\n[+]poststarthook/generic-apiserver-start-informers ok\n[+]poststarthook/priority-and-fairness-config-consumer ok\n[+]poststarthook/priority-and-fairness-filter ok\n[+]poststarthook/start-apiextensions-informers ok\n[+]poststarthook/start-apiextensions-controllers ok\n[+]poststarthook/crd-informer-synced ok\n[+]poststarthook/bootstrap-controller ok\n[+]poststarthook/rbac/bootstrap-roles ok\n[+]poststarthook/scheduling/bootstrap-system-priority-classes ok\n[+]poststarthook/priority-and-fairness-config-producer ok\n[+]poststarthook/start-cluster-authentication-info-controller ok\n[+]poststarthook/aggregator-reload-proxy-client-cert ok\n[+]poststarthook/start-kube-aggregator-informers ok\n[+]poststarthook/apiservice-registration-controller ok\n[+]poststarthook/apiservice-status-available-controller ok\n[+]poststarthook/kube-apiserver-autoregistration ok\n[+]autoregister-completion ok\n[+]poststarthook/apiservice-openapi-controller ok\n[+]poststarthook/apiservice-openapiv3-controller ok\nhealthz check failed") has prevented the request from succeeding status=500
2024-01-31 03:51:24.134 [ERROR][1] main.go 278: Received bad status code from apiserver error=an error on the server ("[+]ping ok\n[+]log ok\n[-]etcd failed: reason withheld\n[+]poststarthook/start-kube-apiserver-admission-initializer ok\n[+]poststarthook/generic-apiserver-start-informers ok\n[+]poststarthook/priority-and-fairness-config-consumer ok\n[+]poststarthook/priority-and-fairness-filter ok\n[+]poststarthook/start-apiextensions-informers ok\n[+]poststarthook/start-apiextensions-controllers ok\n[+]poststarthook/crd-informer-synced ok\n[+]poststarthook/bootstrap-controller ok\n[+]poststarthook/rbac/bootstrap-roles ok\n[+]poststarthook/scheduling/bootstrap-system-priority-classes ok\n[+]poststarthook/priority-and-fairness-config-producer ok\n[+]poststarthook/start-cluster-authentication-info-controller ok\n[+]poststarthook/aggregator-reload-proxy-client-cert ok\n[+]poststarthook/start-kube-aggregator-informers ok\n[+]poststarthook/apiservice-registration-controller ok\n[+]poststarthook/apiservice-status-available-controller ok\n[+]poststarthook/kube-apiserver-autoregistration ok\n[+]autoregister-completion ok\n[+]poststarthook/apiservice-openapi-controller ok\n[+]poststarthook/apiservice-openapiv3-controller ok\nhealthz check failed") has prevented the request from succeeding status=500
2024-01-31 03:51:48.678 [ERROR][1] main.go 278: Received bad status code from apiserver error=an error on the server ("[+]ping ok\n[+]log ok\n[-]etcd failed: reason withheld\n[+]poststarthook/start-kube-apiserver-admission-initializer ok\n[+]poststarthook/generic-apiserver-start-informers ok\n[+]poststarthook/priority-and-fairness-config-consumer ok\n[+]poststarthook/priority-and-fairness-filter ok\n[+]poststarthook/start-apiextensions-informers ok\n[+]poststarthook/start-apiextensions-controllers ok\n[+]poststarthook/crd-informer-synced ok\n[+]poststarthook/bootstrap-controller ok\n[+]poststarthook/rbac/bootstrap-roles ok\n[+]poststarthook/scheduling/bootstrap-system-priority-classes ok\n[+]poststarthook/priority-and-fairness-config-producer ok\n[+]poststarthook/start-cluster-authentication-info-controller ok\n[+]poststarthook/aggregator-reload-proxy-client-cert ok\n[+]poststarthook/start-kube-aggregator-informers ok\n[+]poststarthook/apiservice-registration-controller ok\n[+]poststarthook/apiservice-status-available-controller ok\n[+]poststarthook/kube-apiserver-autoregistration ok\n[+]autoregister-completion ok\n[+]poststarthook/apiservice-openapi-controller ok\n[+]poststarthook/apiservice-openapiv3-controller ok\nhealthz check failed") has prevented the request from succeeding status=500