Rancher Server 设置
- Rancher 版本:
- 安装选项 (Docker install/Helm Chart): Helm Chart ,Local集群类型k3s
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:
- 在线或离线部署:
下游集群信息
- Kubernetes 版本: v1.22.7,v1.20.6-tke.17
- Cluster Type (Local/Downstream):
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等):
用户信息
- 登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义):管理员
主机操作系统:
CentOS Linux release 7.9
问题描述:
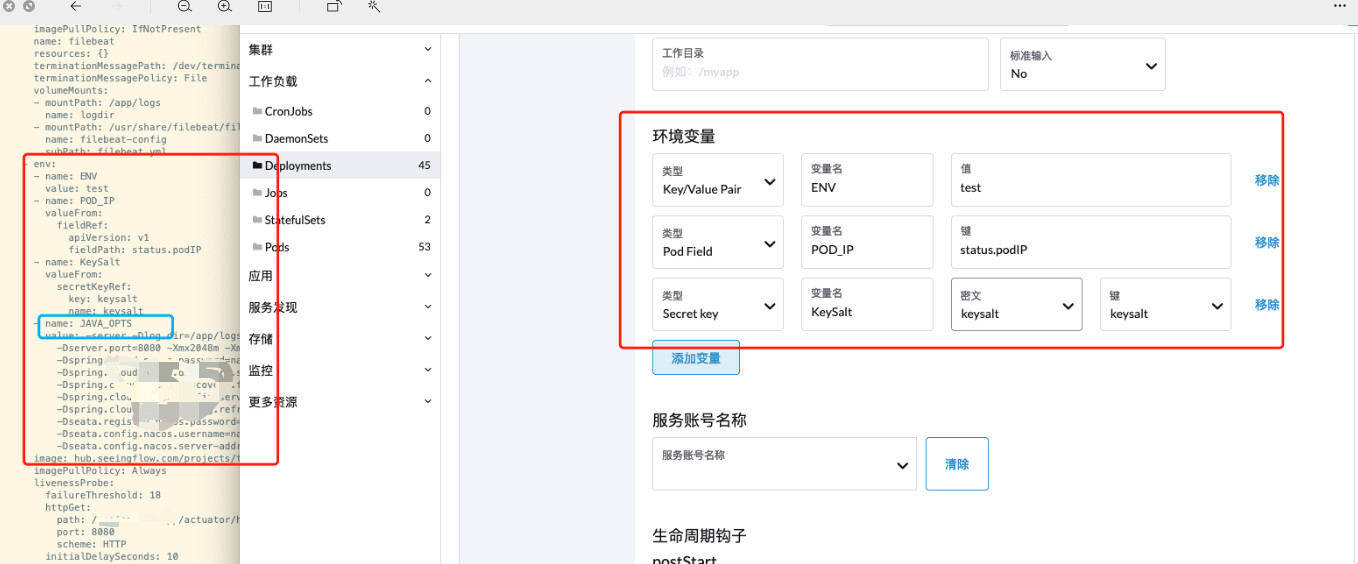
rancher V2.6.7 yaml创建的服务不显示健康检查,太长的变量也不显示,之前 rancherv2.6.5 没有这个问题
重现步骤:
通过yaml创建服务,设置健康检查, 变量
结果:
UI上健康检查显示为空,短变量正常显示, value长的变量不显示
预期结果:
UI上显示的和yaml文件一样
截图:
其他上下文信息:
[details=“日志”]
@gw 能否把有问题的 yaml 配置文件,去掉敏感信息贴出来,这边做个排查?
gw
5
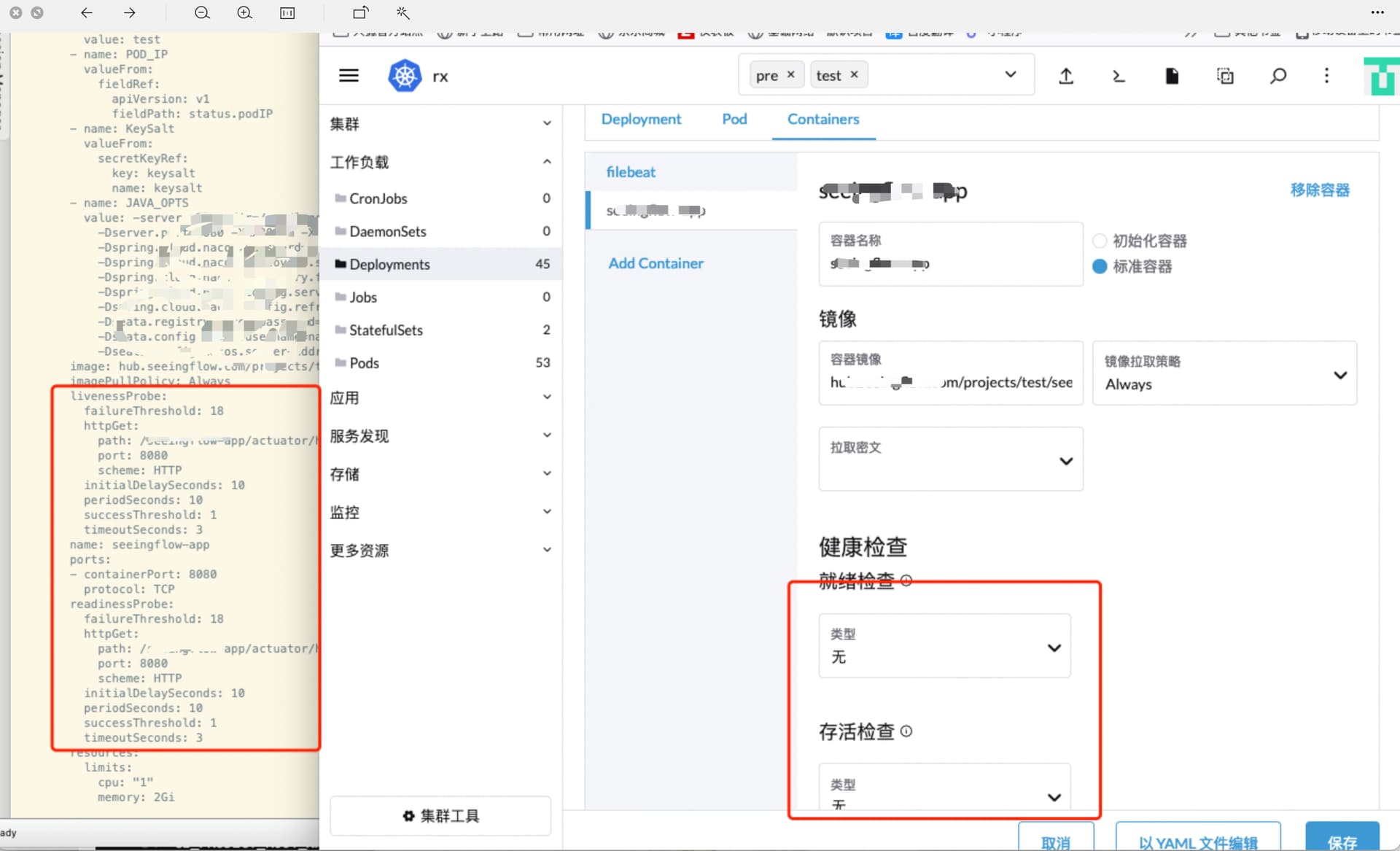
我又测试了一下,发现sidecar 模式下再rancher ui上会显示配置不全, 单独的pod显示没有问题
# sidecar
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
name: test-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: test-demo
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: test-demo
spec:
containers:
- env:
- name: ENV
value: demo
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
image: filebeat
name: filebeat
- env:
- name: ENV
value: demo
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: JAVA_OPTS
value: -server -Dlog.dir=/app/logs -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
-Dserver.port=8080 -Xmx2048m -Xms512m -Dspring.cloud.nacos.username=aaaaa
-Dspring.cloud.nacos.discovery.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dspring.cloud.nacos.discovery.fail-fast=true
-Dspring.cloud.nacos.config.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dspring.cloud.nacos.config.refresh-enabled=true -Dseata.registry.nacos.username=nacos
-Dseata.registry.nacos.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dseata.config.nacos.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
image: nginx
name: nginx
imagePullPolicy: Always
livenessProbe:
failureThreshold: 18
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
name: test-demo
ports:
- containerPort: 80
protocol: TCP
readinessProbe:
failureThreshold: 18
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
resources:
limits:
cpu: "1"
memory: 2Gi
requests:
cpu: 100m
memory: 512Mi
dnsPolicy: ClusterFirst
restartPolicy: Always
# 单独的pod
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
name: test-demo
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: test-demo
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
labels:
app: test-demo
spec:
containers:
- env:
- name: ENV
value: demo
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: JAVA_OPTS
value: -server -Dlog.dir=/app/logs -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp
-Dserver.port=8080 -Xmx2048m -Xms512m -Dspring.cloud.nacos.username=aaaaa
-Dspring.cloud.nacos.discovery.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dspring.cloud.nacos.discovery.fail-fast=true
-Dspring.cloud.nacos.config.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dspring.cloud.nacos.config.refresh-enabled=true -Dseata.registry.nacos.username=nacos
-Dseata.registry.nacos.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
-Dseata.config.nacos.server-addr=nacos1.server.sf:8848,nacos2.server.sf:8848,nacos3.server.sf:8848
image: nginx
name: nginx
imagePullPolicy: Always
livenessProbe:
failureThreshold: 18
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
name: test-demo
ports:
- containerPort: 80
protocol: TCP
readinessProbe:
failureThreshold: 18
httpGet:
path: /index.html
port: 80
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 3
resources:
limits:
cpu: "1"
memory: 2Gi
requests:
cpu: 100m
memory: 512Mi
dnsPolicy: ClusterFirst
restartPolicy: Always
@gw
感谢给出样例 yaml 配置,经排查,这个问题与这个 issue 类似,当 workload 有多个容器时,切换容器对应的 tab 页面时,表单没有同步,导致环境变量等表单始终显示上一个容器对应的表单内容,这个issue 对应的 PR 已经合并到了 dashboard ui 的主分支里,将在下一个版本 v2.6.9 中修复,敬请关注。