注意:
- 本指南只适用于 v2.6 的 Rancher 版本,如修改 v2.5 或以下版本,可参考:https://mp.weixin.qq.com/s/YzsGaMMs5rwEHQ2ZFASJeA
- 本指南为非官方操作,操作前请务必做好备份
- 本文内容展示的 IP 和密钥信息均为临时测试环境使用
前言
在之前发布的 如何修改 Rancher Server 的 IP 地址 文章中介绍了如何修改 Rancher v2.5 及以下版本的 Rancher Server 地址。因为 Rancher v2.6 和 v2.5 的修改方式不同,所以单独写一篇文章来介绍如何修改 Rancher v2.6 版本的 Rancher Server 地址。
Rancher 管理的每个下游用户集群都有一个 cluster agent,它建立了一个 tunnel,并通过这个 tunnel 连接到 Rancher Server 中相应的集群控制器(Cluster controller)。
Cluster agent,也称为 cattle-cluster-agent,是在下游用户集群中运行的组件。它其中的一个非常重要的作用就是:在下游用户集群和 Rancher Server 之间(通过到集群控制器的 tunnel)就事件、统计信息、节点信息和健康状况进行通信并上报.

如果当 Rancher Server 的 IP 发生变化,cattle-cluster-agent 无法通过 tunnel 连接到 Rancher Server,你可以在下游集群的 cattle-cluster-agent 容器中查看到如下日志:
time="2022-06-02T02:42:56Z" level=error msg="Failed to connect to proxy. Empty dialer response" error="dial tcp 3.99.162.40:443: i/o timeout"
time="2022-06-02T02:42:56Z" level=error msg="Remotedialer proxy error" error="dial tcp 3.99.162.40:443: i/o timeout"
time="2022-06-02T02:42:56Z" level=error msg="Failed to dial steve aggregation server: dial tcp 3.99.162.40:443: i/o timeout"
3.99.162.40 为原 Rancher Server IP
Rancher UI 将显示集群状态为 Unavailable:

可以看出,Rancher Server 的主机的 IP 发生变化后,Rancher Agent 无法通过原来的 Rancher Server IP 去连接,所以我们需要更新 Rancher Agent 连接 Rancher Server 的 IP 地址。
重新创建 Rancher Agent,使 Rancher Agent 连接到新 Rancher Server IP
更新 server-url
因为 Rancher Server 节点的 IP 地址发生变化,所以需要更新 Rancher Server 的 server-url 为正确的主机 IP(本例将 3.99.162.40 修改为:3.96.51.247 )。我们可以从 Global Settings 中找到 server-url 的选项。

获取下游集群的 kubeconfig
重新创建 Rancher Agent 需要通过 kubectl 连接下游集群,所以在操作前,首先需要获取下游集群的 kubeconfig 文件。
可以从以下三种方式中任选其一:
- 如果你已经从 Rancher UI 上下载了下游集群的 kubeconfig。由于 Rancher 已经和下游集群失联,所以你无法继续使用 rancher api 连接下游集群。但你可以通过切换 context 直接连接到下游集群 kube-apiserver 继续操作下游集群,参考: 直接使用下游集群进行身份验证
- 在 Rancher Server 容器的 secret 中获取,参考:https://gist.github.com/superseb/f6cd637a7ad556124132ca39961789a4
- 在具有控制平面角色的节点上生成 kubeconfig,参考:rancher 2.4/5 生产kubeconfig文件 · GitHub
重新生成 Rancher Agent 定义
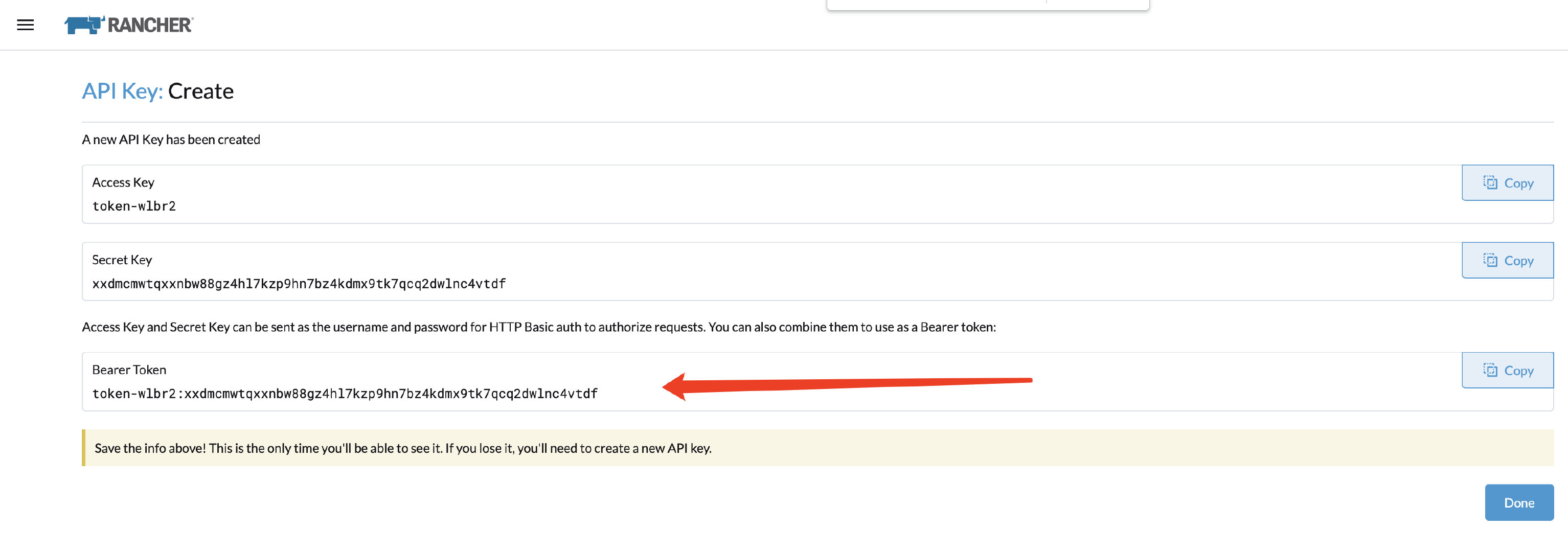
在 UI 中生成 API 令牌(User → Account and API Keys)并保存 Bearer Token;
本例为:token-wlbr2:xxdmcmwtqxxnbw88gz4hl7kzp9hn7bz4kdmx9tk7qcq2dwlnc4vtdf
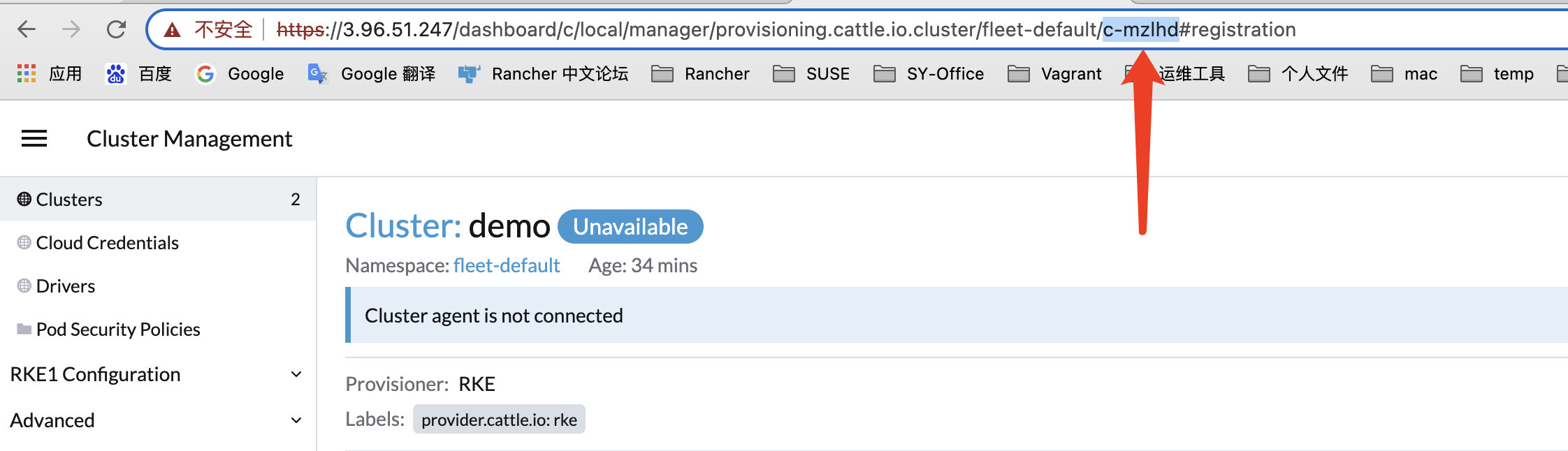
在 Rancher UI 中找到 clusterid(格式为 c-xxxxx)。如果你不知道如何查找 clusterid,导航到 Cluster Management,点击对应的集群名称,此时,浏览器地址栏将会显示一个 c-xxxxx 的 clusterid。
本例为:c-mzlhd
生成 agent 定义(需要 curl, jq)
# Rancher URL
RANCHERURL="https://3.96.51.247"
# Cluster ID
CLUSTERID="c-mzlhd"
# Token
TOKEN="token-wlbr2:xxdmcmwtqxxnbw88gz4hl7kzp9hn7bz4kdmx9tk7qcq2dwlnc4vtdf"
# 如果你的 Rancher Server 是有效证书,请执行:
curl -s -H "Authorization: Bearer ${TOKEN}" "${RANCHERURL}/v3/clusterregistrationtokens?clusterId=${CLUSTERID}" | jq -r '.data[] | select(.name != "system") | .command'
# 如果你的 Rancher Server 是自签名证书,请执行:
curl -s -k -H "Authorization: Bearer ${TOKEN}" "${RANCHERURL}/v3/clusterregistrationtokens?clusterId=${CLUSTERID}" | jq -r '.data[] | select(.name != "system") | .insecureCommand'
成功执行后,将生成一个执行定义的命令,例如:
~# RANCHERURL="https://3.96.51.247"
~# CLUSTERID="c-mzlhd"
~# TOKEN="token-wlbr2:xxdmcmwtqxxnbw88gz4hl7kzp9hn7bz4kdmx9tk7qcq2dwlnc4vtdf"
~# curl -s -k -H "Authorization: Bearer ${TOKEN}" "${RANCHERURL}/v3/clusterregistrationtokens?clusterId=${CLUSTERID}" | jq -r '.data[] | select(.name != "system") | .insecureCommand'
curl --insecure -sfL https://3.96.51.247/v3/import/mkqvrr5gqdcsp5s7hrd9nfwnncwskr4d2xjs9x47hf57kvpkbx7q4x_c-mzlhd.yaml | kubectl apply -f -
应用定义
在具有 kubectl 和 kubeconfig 的主机上执行上一步生成的重新配置 Rancher Agent 的命令:
~# curl --insecure -sfL https://3.96.51.247/v3/import/mkqvrr5gqdcsp5s7hrd9nfwnncwskr4d2xjs9x47hf57kvpkbx7q4x_c-mzlhd.yaml | kubectl apply -f -
clusterrole.rbac.authorization.k8s.io/proxy-clusterrole-kubeapiserver unchanged
clusterrolebinding.rbac.authorization.k8s.io/proxy-role-binding-kubernetes-master unchanged
namespace/cattle-system unchanged
serviceaccount/cattle unchanged
clusterrolebinding.rbac.authorization.k8s.io/cattle-admin-binding unchanged
secret/cattle-credentials-a3725a3 created
clusterrole.rbac.authorization.k8s.io/cattle-admin unchanged
Warning: spec.template.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms[0].matchExpressions[0].key: beta.kubernetes.io/os is deprecated since v1.14; use "kubernetes.io/os" instead
deployment.apps/cattle-cluster-agent configured
daemonset.apps/cattle-node-agent configured
service/cattle-cluster-agent unchanged
验证 Rancher Agent 连接
稍等片刻,cattle-cluster-agent和cattle-node-agent 将会重新运行,并连接到正确的 Rancher Server 地址:
~# kubectl -n cattle-system get pods
NAME READY STATUS RESTARTS AGE
cattle-cluster-agent-59c7b49f66-ktxsb 1/1 Running 0 114s
cattle-node-agent-gf9cw 1/1 Running 0 83s
~# kubectl -n cattle-system logs -f cattle-cluster-agent-59c7b49f66-ktxsb
...
...
INFO: https://3.96.51.247/ping is accessible
INFO: Value from https://3.96.51.247/v3/settings/cacerts is an x509 certificate
time="2022-06-02T02:59:32Z" level=info msg="Listening on /tmp/log.sock"
time="2022-06-02T02:59:32Z" level=info msg="Rancher Agent version v2.6.5 is starting"
time="2022-06-02T02:59:32Z" level=info msg="Connecting to wss://3.96.51.247/v3/connect/register with token starting with mkqvrr5gqdcsp5s7hrd9nfwnncw"
time="2022-06-02T02:59:32Z" level=info msg="Connecting to proxy" url="wss://3.96.51.247/v3/connect/register"
~# kubectl -n cattle-system logs -f cattle-node-agent-gf9cw
...
...
time="2022-06-02T03:00:03Z" level=info msg="Option etcd=false"
time="2022-06-02T03:00:03Z" level=info msg="Connecting to wss://3.96.51.247/v3/connect with token starting with mkqvrr5gqdcsp5s7hrd9nfwnncw"
time="2022-06-02T03:00:03Z" level=info msg="Connecting to proxy" url="wss://3.96.51.247/v3/connect"
time="2022-06-02T03:00:03Z" level=info msg="Starting plan monitor, checking every 120 seconds"
重置下游集群配置
虽然 Rancher Agent 已经连接到正确的 Rancher Server 地址,但 UI 上对应的下游集群的状态依然是 Unavailable。为了将集群状态恢复到 Active 状态,我们还需要重置 Rancher 管理的每个下游集群( Rancher Local 管理集群除外)的配置。
重置下游集群的配置也很简单,只需要登录的 local 集群执行以下命令即可:
kubectl patch clusters.management.cattle.io <REPLACE_WITH_CLUSTERID> -p '{"status":{"agentImage":"dummy"}}' --type merge
这是一个完整的示例:
# 由于我的环境是单节点安装的 Rancher Server,要登录到 local 集群只需要 exec 到 Rancher Server 重启中即可。
root@ip-172-31-3-48:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
c00bebf88aae rancher/rancher "entrypoint.sh" 58 minutes ago Up 38 minutes 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp wonderful_ishizaka
root@ip-172-31-3-48:~# docker exec -it c00 bash
c00bebf88aae:/var/lib/rancher # CLUSTERID="c-mzlhd"
c00bebf88aae:/var/lib/rancher # kubectl patch clusters.management.cattle.io ${CLUSTERID} -p '{"status":{"agentImage":"dummy"}}' --type merge
cluster.management.cattle.io/c-mzlhd patched
此时,Rancher 管理的下游集群状态已经变为 Active 状态:

重置 fleet-agent
虽然现在集群的状态已经恢复为 Active 状态,但 fleet-agent 启动报错,连接的的 fleet-controller 地址依然是原来的 Rancher Server 地址:
~# kubectl get pods -n cattle-fleet-system
NAME READY STATUS RESTARTS AGE
fleet-agent-55b948fdd7-gnbm7 1/1 Running 0 55m
~# kubectl logs -f fleet-agent-55b948fdd7-gnbm7 -n cattle-fleet-system
...
...
time="2022-06-02T03:09:34Z" level=error msg="failed to report cluster node status: Patch \"https://3.99.162.40/apis/fleet.cattle.io/v1alpha1/namespaces/fleet-default/clusters/c-mzlhd/status\": dial tcp 3.99.162.40:443: i/o timeout"
所以,我们还需要重置 fleet-agent 连接的 fleet-controller 地址,重置的方法可以直接在 Rancher UI 上操作即可:
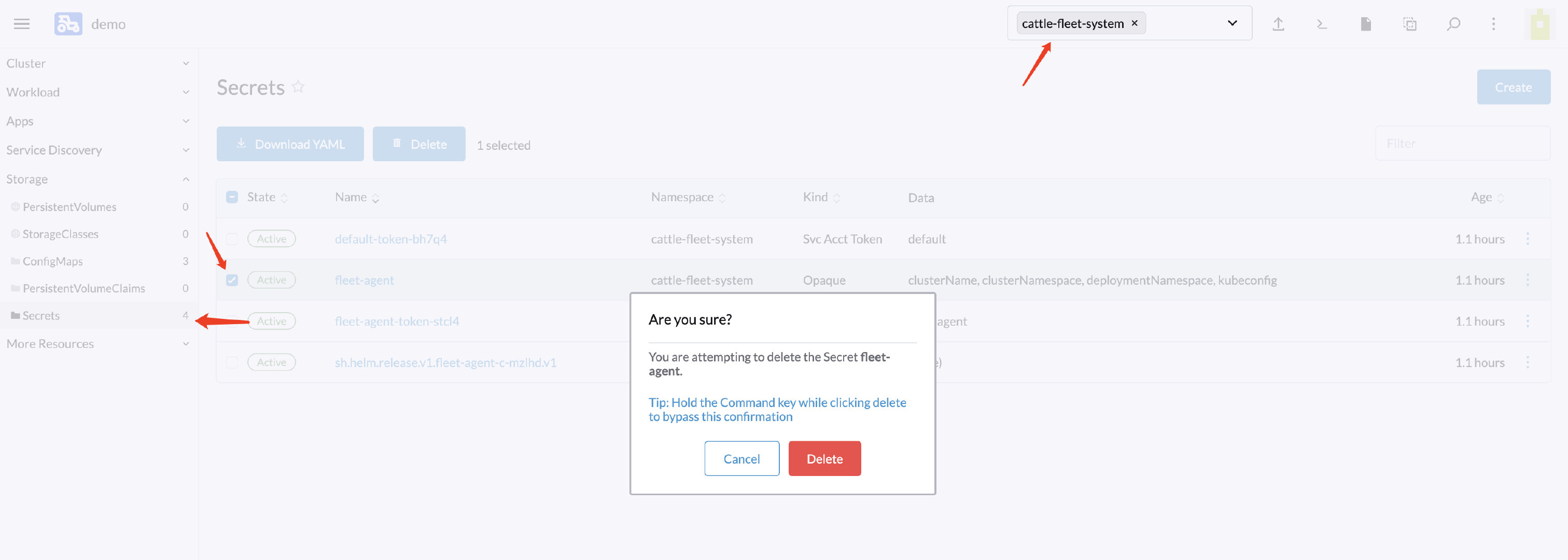
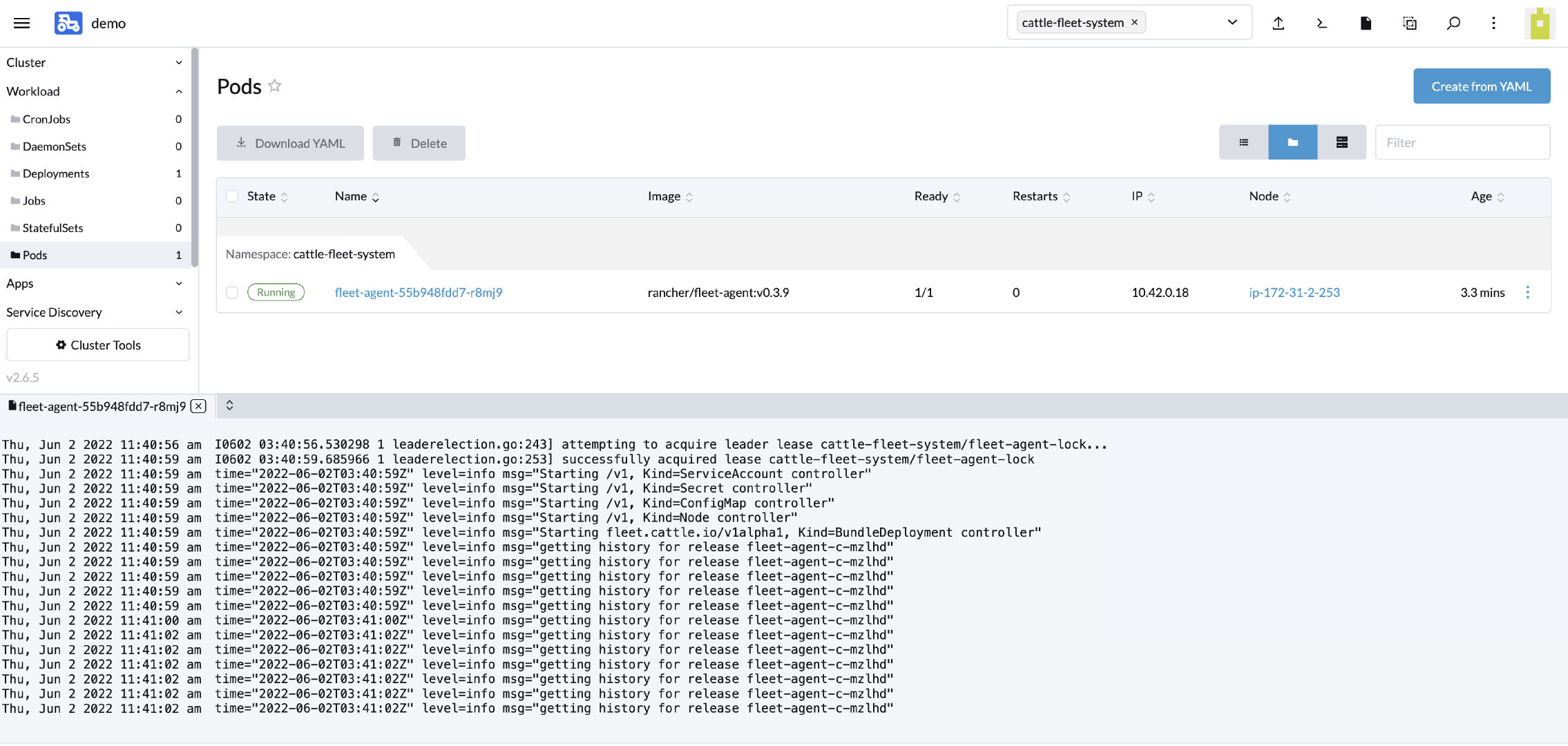
首先,从 Rancher UI 导航到下游集群的 Secret 页面,切换到 cattle-fleet-system 命名空间 ,找到 fleet-agent 并删除;
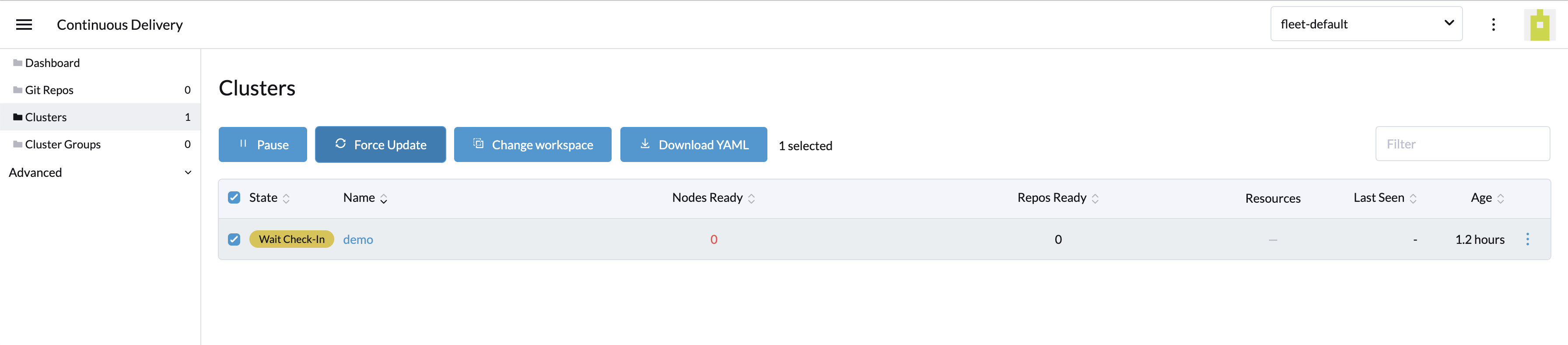
然后,导航到 首页-Continuous Delivery-Cluster,选中对应的集群点击 Force Update,来触发下游集群的更新;
最后,更新成功后,集群状态恢复为 Active 状态,fleet-agent 也随之成功启动:
后记
个人非常不建议去修改 Rancher Server 的 IP 地址,甚至 server-url 的修改也有可能带来隐患。
即使是单节点安装的 Rancher Server,也建议通过域名去注册下游集群,这样后续我们可以从单节点迁移到高可用,或者 Rancher Server 节点 IP 有变动后,只需要修改对应的 IP 映射即可。