Rancher Server 设置
- Rancher 版本: v2.7.0
- 安装选项 (Docker install/Helm Chart): Helm Chart
- RKE1 - 版本:v1.24.8
下游集群信息
- Kubernetes 版本: v1.24.8
- Cluster Type (Local/Downstream): Downstream
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): RKE 自定义/导入
用户信息
- 登录用户的角色是什么? (管理员/集群所有者/集群成员/项目所有者/项目成员/自定义): admin
主机操作系统:SLES15 SP3
问题描述:
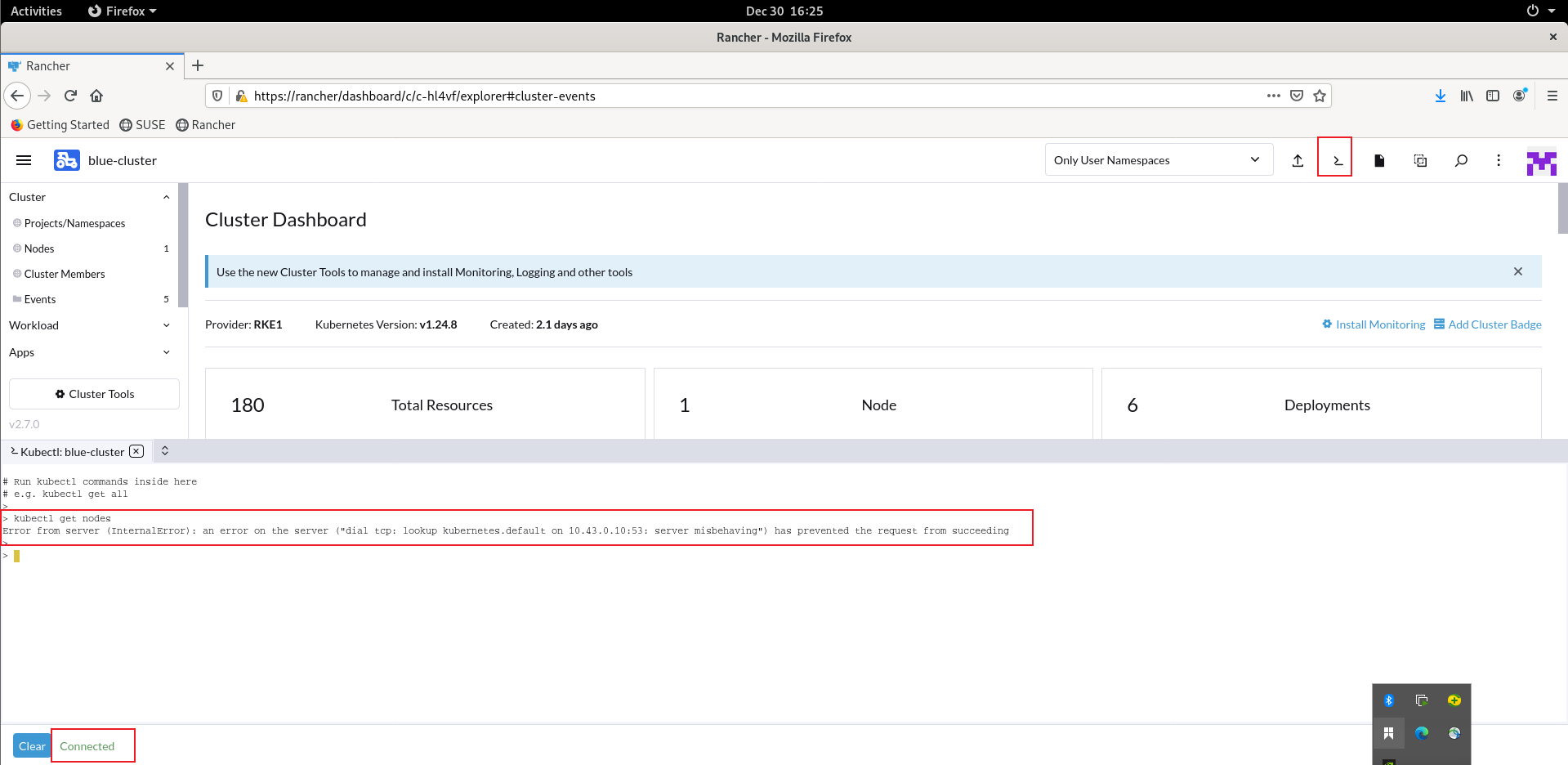
在 Rancher WebUI → 下游集群中,打开 ‘kubectl shell’,是 connected 状态,但无法正常执行 kubectl 命令,返回信息如下,
kubectl get nodes
Error from server (InternalError): an error on the server (“dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving”) has prevented the request from succeeding
截图:
其他上下文信息:
将下游集群 blue-cluster 的 kubeconfig 文件下载至 Rancher server 所在的宿主机中,可正常执行 kubectl 命令,
rke-master:~/.kube # kubectl get pods --kubeconfig blue-cluster.kubeconfig
NAME READY STATUS RESTARTS AGE
web-server 1/1 Running 0 51m
在 Rancher WebUI → 下游集群 → Workload → Pods 中,对 pod 可正常打开 “Execute Shell”,
root@web-server:/usr/local/apache2# cat htdocs/index.html
It works!
root@web-server:/usr/local/apache2#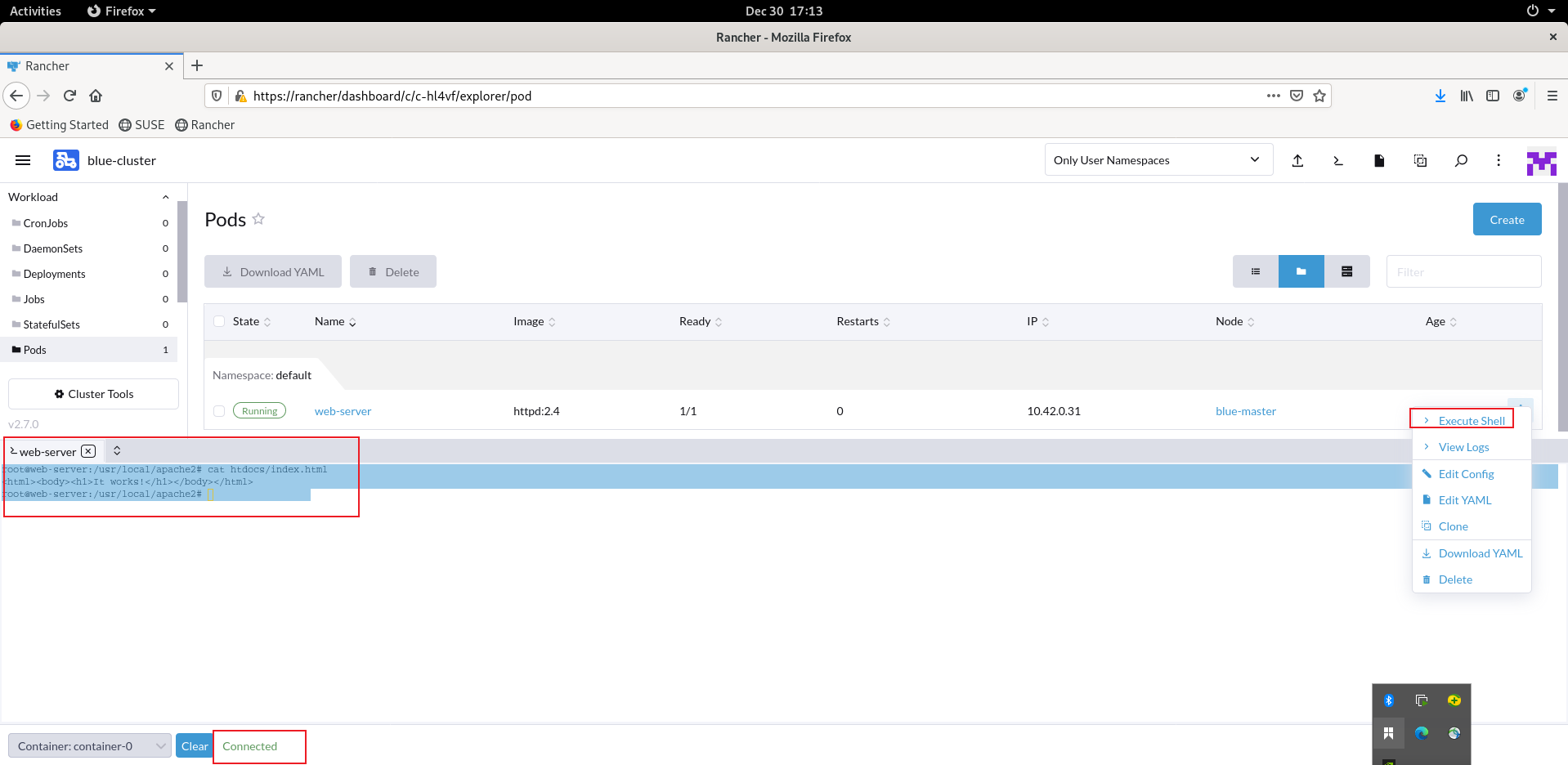
日志
blue-master:~ # docker logs k8s_proxy_dashboard-shell-4k2dq_cattle-system_6ecc4f04-e5a7-4ae3-b888-1b9f2b5b8ed9_0
W1230 08:19:59.823135 6 proxy.go:162] Request filter disabled, your proxy is vulnerable to XSRF attacks, please be cautious
Starting to serve on 127.0.0.1:8001
E1230 08:24:14.331524 6 proxy_server.go:147] Error while proxying request: dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving
E1230 08:24:14.339816 6 proxy_server.go:147] Error while proxying request: dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving
E1230 08:24:14.349768 6 proxy_server.go:147] Error while proxying request: dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving
E1230 08:24:14.357557 6 proxy_server.go:147] Error while proxying request: dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving
E1230 08:24:14.366064 6 proxy_server.go:147] Error while proxying request: dial tcp: lookup kubernetes.default on 10.43.0.10:53: server misbehaving
请帮忙看看是否需要在 Rancher Server 中做哪些设置,谢谢,