Rancher Server 设置
- Rancher 版本:rancher 2.6.6
- 安装选项 (Docker install/Helm Chart): Helm Chart
- 如果是 Helm Chart 安装,需要提供 Local 集群的类型(RKE1, RKE2, k3s, EKS, 等)和版本:RKE1
- 在线或离线部署:在线部署
下游集群信息
- Kubernetes 版本: rke v1.20.15
- Cluster Type (Local/Downstream): Downstream
- 如果 Downstream,是什么类型的集群?(自定义/导入或为托管 等): 自定义
主机操作系统:
CentOS7.9
问题描述:
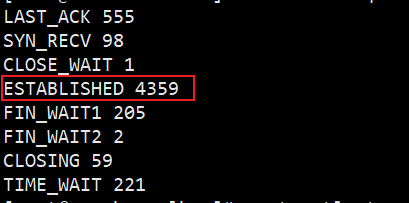
rancher集群部署在公司内,我现在rancher中有50个左右下游集群,导致我的网络连接丢包比较严重,我关闭rancher集群的访问入口后网络即恢复正常,不再丢包,应该是我接入路由器的问题。我有什么办法可以优化这个现象吗?或者我必须升级我的路由器才能解决这个问题?下面是代理rancher的nginx的连接:
重现步骤:
结果:
预期结果:
截图:
其他上下文信息:
日志