
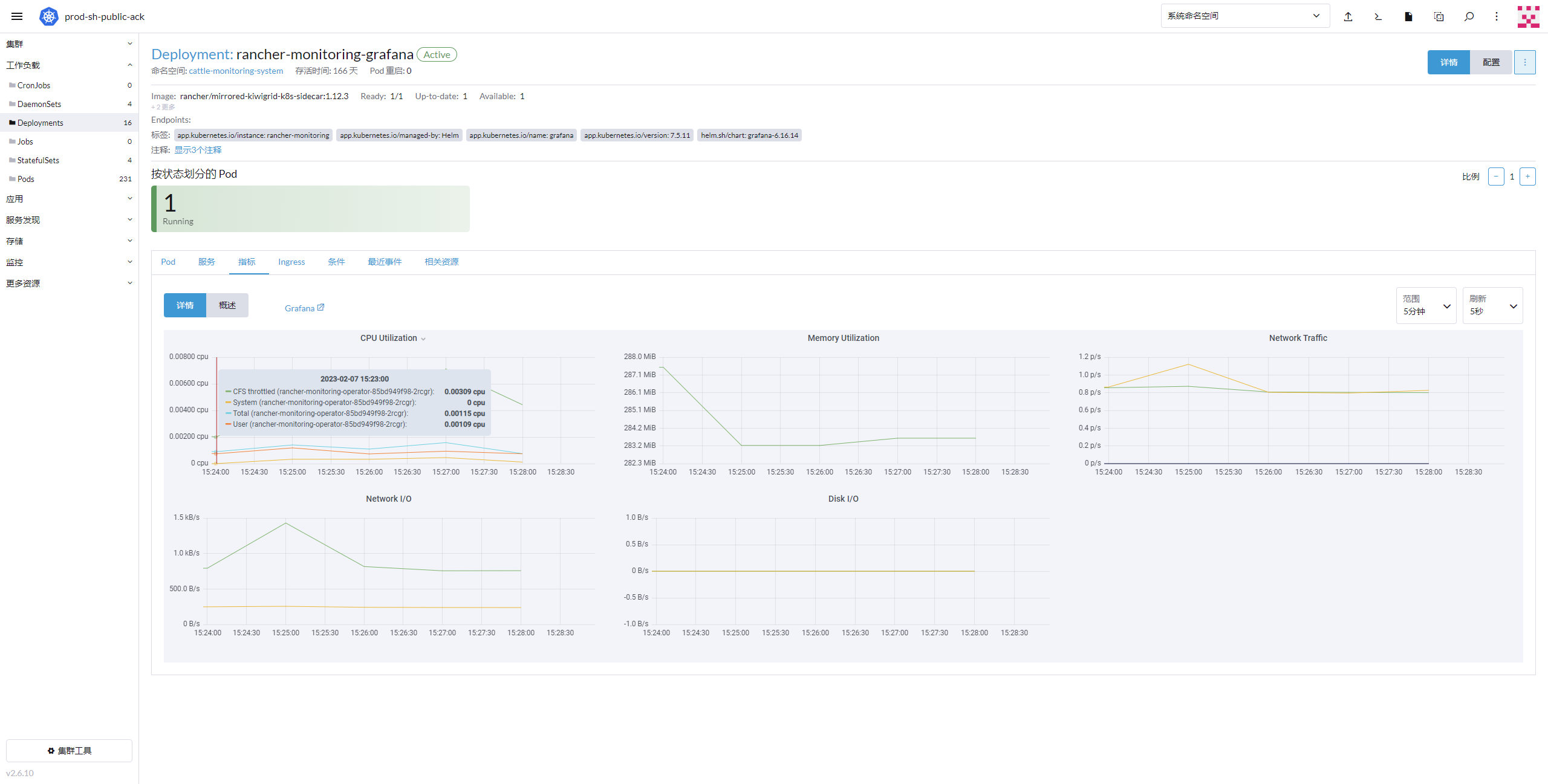
1.打开deployment指标时,默认的30S刷新的仪表盘数据不显示,只能把刷新时间调到5S刷新后,数据才显示。
2.工作负载的监控数值显示不准确,是prometheus语法的问题,值比实际大了一倍
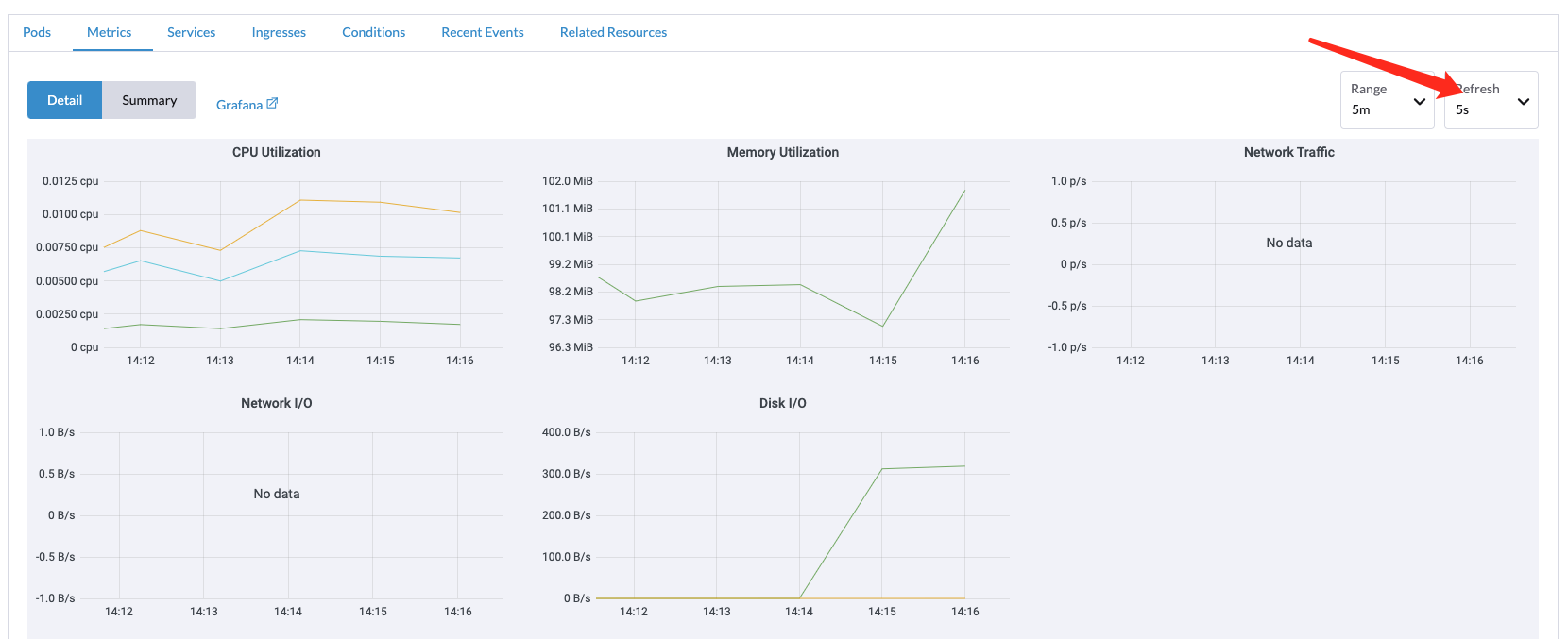
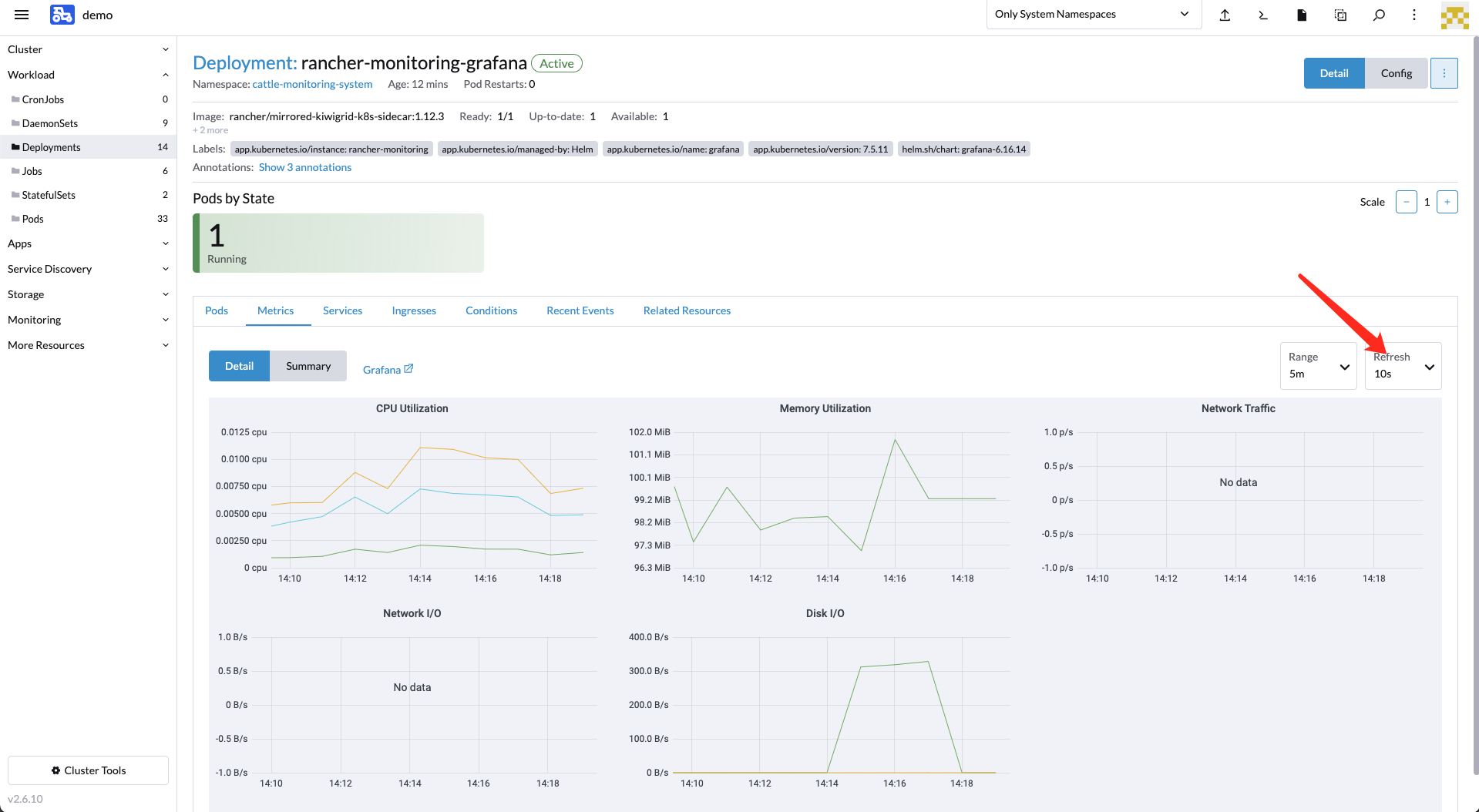
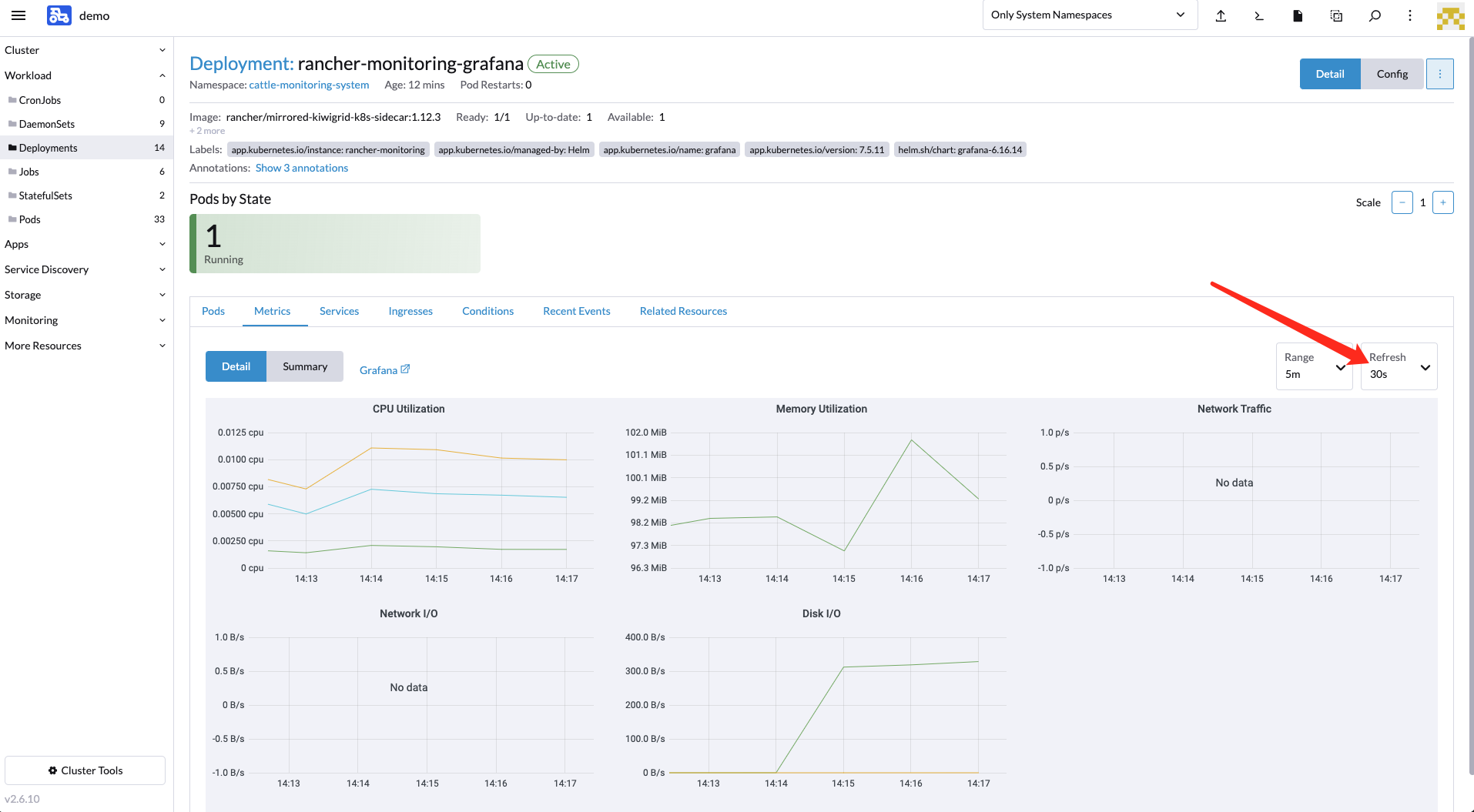
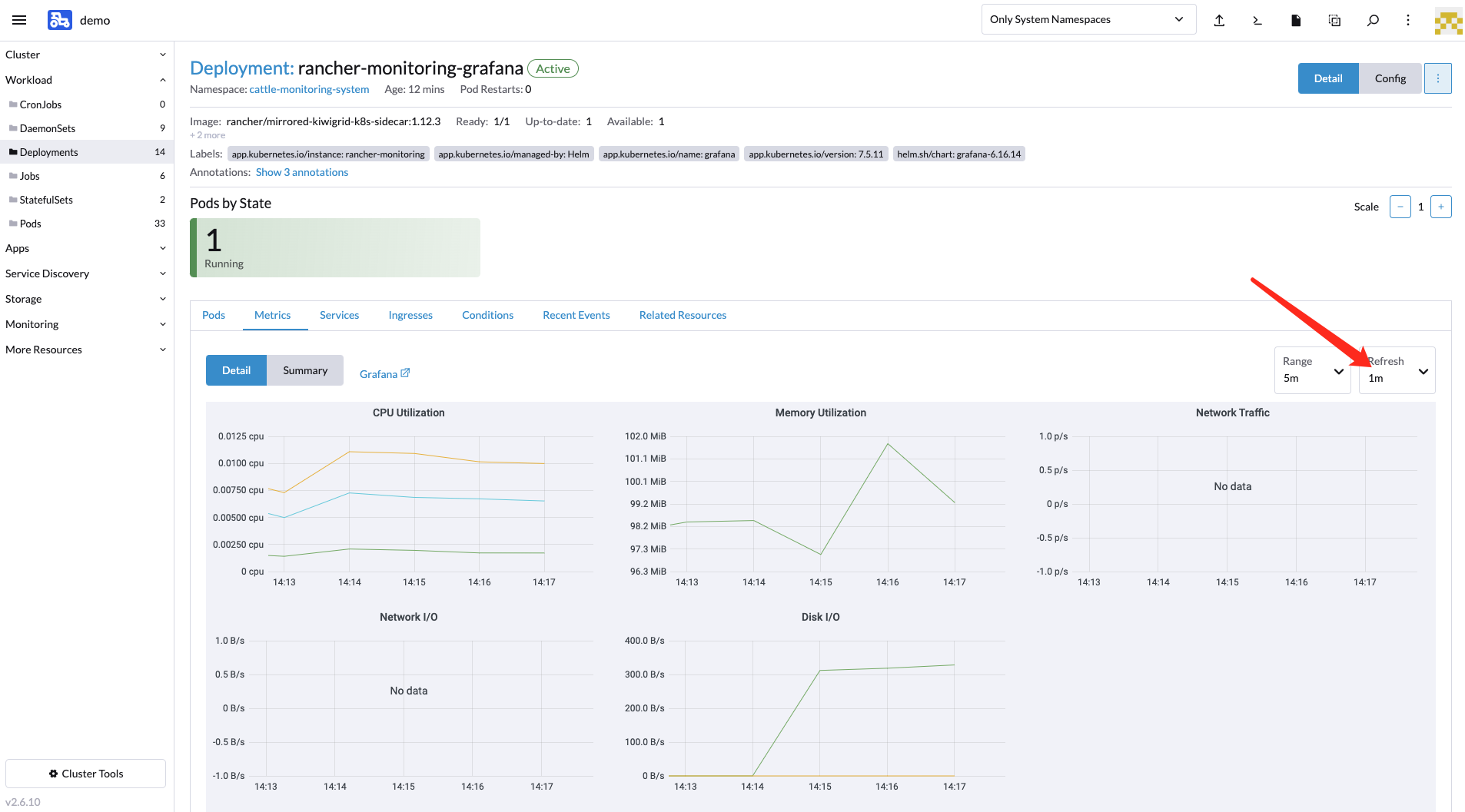
我这边的接入集群是阿里云的ack和自建的k3s没有数据,需要等到刷新周期时间后才会显示

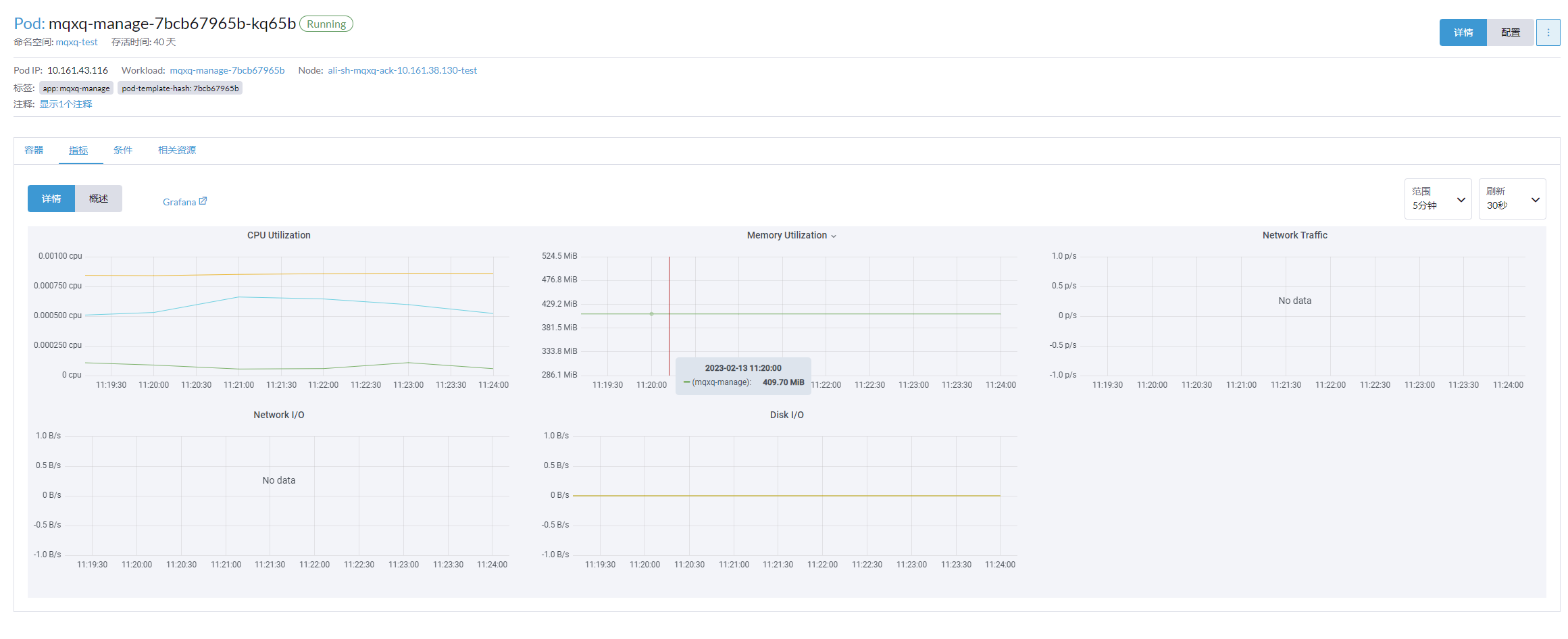
v2.7.x版本监控指标也是一样存在这个问题,查看的时候不显示,过了刷新时间才出来,而且和主机上看到的内存资源占用相差很大
我这个2.7.4 也是会出现,一到刷新点 数据被清空然后又出来了, 最重要的是 deployment 的监控数值比pod的大一倍,不知道怎么调整回来
怎么解决这个 deployment 的监控数值比pod的大一倍的问题呀 ?
亲,请问这问题你那解决了吗
如果着急的话,可以到 github 上创建个 issue,论坛只有国内工程师能看见,并且监控是由国外工程师负责的
使用2.6.10-2.7.6 都有这个问题 ,有些监控统计不准确,比如rancher页面上统计的,
单容器的监控 Rancher/pod 这个是准确的
但是 看deploy 监控 Rancher/Workload(Pods) 这个不准确(是普通的2倍)
Kubernetes/Compute Resources/Workload 这个是准确的