环境信息:
RKE2 版本: rke2 v1.26.5+rke2r1 Rancher 2.7.5
节点 CPU 架构,操作系统和版本:
Centos 7.9集群配置:3 servers
问题描述:
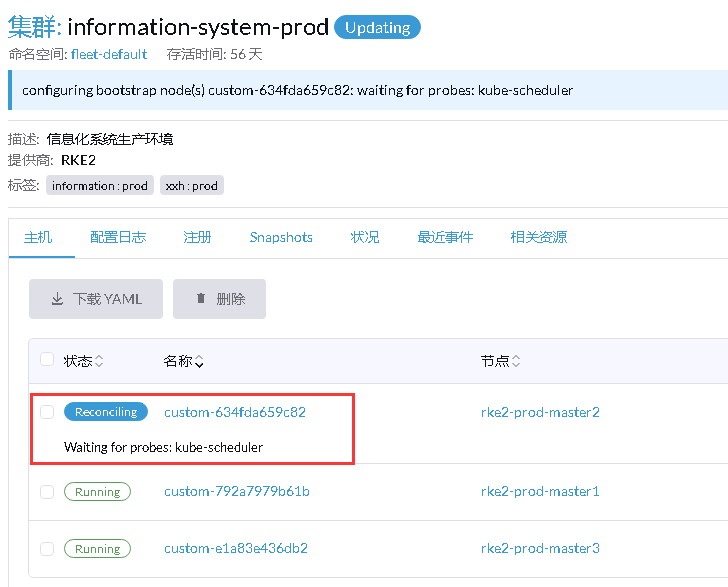
1、因磁盘挂载问题将RKE2下游集群3台server节点逐次离线删除并重新加入集群,集群恢复后,执行kubectl命令就会报错,如下图所示

2、在Rancher UI上Deployment点击进入POD,页面一直卡着不动,一段时间后有时候能加载成功,有时候失败。

重现步骤:
- 安装 RKE2 的命令:
预期结果:
页面点击流畅操作,不会有告警提示
实际结果:
日志
E1205 11:48:57.918699 23290 memcache.go:287] couldn’t get resource list for custom.metrics.k8s.io/v1beta1: the server is currently unable to handle the request
E1205 11:48:57.924786 23290 memcache.go:121] couldn’t get resource list for custom.metrics.k8s.io/v1beta1: the server is currently unable to handle the request
E1205 11:48:57.930510 23290 memcache.go:121] couldn’t get resource list for custom.metrics.k8s.io/v1beta1: the server is currently unable to handle the request
E1205 11:48:57.934266 23290 memcache.go:121] couldn’t get resource list for custom.metrics.k8s.io/v1beta1: the server is currently unable to handle the request