环境信息:
K3s 版本:
k3s version v1.30.0+k3s1 (14549535)
go version go1.22.2
节点 CPU 架构、操作系统和版本::
04节点
uname-a:
Linux master04 5.10.0-60.18.0.50.oe2203.x86_64 #1 SMP Wed Mar 30 03:12:24 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
cat /etc/os-release
NAME=“openEuler”
VERSION=“22.03 LTS”
ID=“openEuler”
VERSION_ID=“22.03”
PRETTY_NAME=“openEuler 22.03 LTS”
ANSI_COLOR=“0;31”
01节点uname-a:
Linux master01 5.10.0-60.18.0.50.oe2203.x86_64 #1 SMP Wed Mar 30 03:12:24 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
cat /etc/os-release
NAME=“openEuler”
VERSION=“22.03 LTS”
ID=“openEuler”
VERSION_ID=“22.03”
PRETTY_NAME=“openEuler 22.03 LTS”
ANSI_COLOR=“0;31”
集群配置:
2 servers
问题描述:
在所有节点的udp8472端口已open的情况下,高可用集群内的service无法访问其他节点中的service
复现步骤:
- 安装 K3s 的命令:
01节点:
INSTALL_K3S_SKIP_DOWNLOAD=true INSTALL_K3S_EXEC=‘server’ K3S_DATASTORE_ENDPOINT=“mysql://test3s:test3s@tcp(172.26.200.196:3306)/K3S” ./install.sh
04节点
INSTALL_K3S_SKIP_DOWNLOAD=true INSTALL_K3S_EXEC=‘server’ K3S_TOKEN=K10dc627dc919bd01a1a8ac5603f9463432c982b5df06a20837c9c31afca876d347::server:c124ea258d7526e25e53c50781be71a9 K3S_DATASTORE_ENDPOINT=“mysql://test3s:test3s@tcp(172.26.200.196:3306)/K3S” ./install.sh
预期结果:
实际结果:
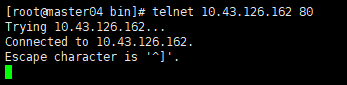
service的IP 10.43.126.162

下图所示,将该service的pod调度到04节点
在01节点上telnet service的IP是不通的

04节点是通的
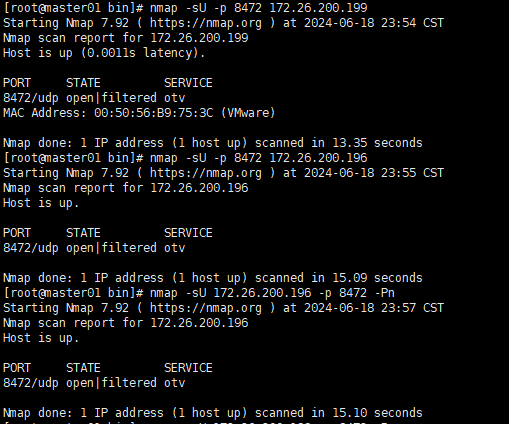
在节点上使用nmap扫描可以看到两个节点的8472端口open
附加上下文/日志:
日志
尝试这个
touch /etc/NetworkManager/conf.d/k3s-canal.conf
cat >> /etc/NetworkManager/conf.d/k3s-canal.conf << EOF
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:flannel*
EOF
systemctl disable nm-cloud-setup.service nm-cloud-setup.timer
systemctl reload NetworkManager
或者你尝试一下这个文档里面的方法 https://docs.k3s.io/installation/requirements#operating-systems
systemctl disable firewalld --now
或者
firewall-cmd --permanent --add-port=6443/tcp #apiserver
firewall-cmd --permanent --zone=trusted --add-source=10.42.0.0/16 #pods
firewall-cmd --permanent --zone=trusted --add-source=10.43.0.0/16 #services
firewall-cmd --reload
感谢回复,集群内所有服务器的防火墙都是关闭的。
目前集群内只有第一个节点可以正常跨节点通信(因为我将service所在的pod调度到其他节点是可以访问的)后面加入的节点都不行
下面的helm-install-traefik那两个pod在我本地测试环境也是Completed状态,但是本地跨节点访问没有问题。出现问题的环境是生产环境
[root@master02 bin]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
local-path-provisioner-75bb9ff978-9p7qw 1/1 Running 0 39m
svclb-traefik-f360d4bc-rj8h4 2/2 Running 0 39m
helm-install-traefik-crd-8b2g9 0/1 Completed 0 39m
helm-install-traefik-9sd2b 0/1 Completed 1 39m
coredns-576bfc4dc7-v8qnf 1/1 Running 0 39m
traefik-5fb479b77-wkj55 1/1 Running 0 39m
metrics-server-557ff575fb-rstl5 1/1 Running 0 39m
svclb-traefik-f360d4bc-bx52c 2/2 Running 0 36m
下面是使用busybox进入pod内部ping其他节点的输出
/ # clear
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 4A:D6:9A:A0:2A:BE
inet addr:10.42.0.32 Bcast:10.42.0.255 Mask:255.255.255.0
inet6 addr: fe80::48d6:9aff:fea0:2abe/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1450 Metric:1
RX packets:35 errors:0 dropped:0 overruns:0 frame:0
TX packets:24 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:2710 (2.6 KiB) TX bytes:1872 (1.8 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # ping 10.42.1.28
PING 10.42.1.28 (10.42.1.28): 56 data bytes
64 bytes from 10.42.1.28: seq=0 ttl=62 time=0.614 ms
64 bytes from 10.42.1.28: seq=1 ttl=62 time=0.471 ms
^C
--- 10.42.1.28 ping statistics ---
2 packets transmitted, 2 packets received, 0% packet loss
round-trip min/avg/max = 0.471/0.542/0.614 ms
可能不是配置问题,安装方式是没有问题的。生产环境问题最好还是在能在对应的环境上做排查,否则很难定位问题
k8s网络层排查,一般按照 node to node, pod to node, pod to pod这三步走,基础网络环境没有问题,则排查 iptables中service是否如期望配置,iptables -t nat -nL |grep 去逐步排查
在我新建的busybox pod中可以ping通其他节点的宿主机地址和pod地址,但是telnet其他节点上的pod端口不通,这个需要从哪方面排查呢,我是k8s及k3s的初学者,还请不吝赐教。
以下是,其中一个service的iptable
[root@master01 opt]# iptables -t nat -nL | grep 10.43.106.177
KUBE-SVC-FQBRBSG6GQH2QJLM tcp -- 0.0.0.0/0 10.43.106.177 /* health-njfybjy/restful-reglog:http cluster IP */ tcp dpt:80
KUBE-MARK-MASQ tcp -- !10.42.0.0/16 10.43.106.177 /* health-njfybjy/restful-reglog:http cluster IP */ tcp dpt:80
这种情况,大概率还是网络策略问题,检查 iptables -nL,看看是否有拦截非ICMP类型的规则。如果没有异常的情况下,只能通过在主机两侧做tcpdump,看看 telnet的数据包被哪里拦截了

